前言:x86 汇编语言是 x86 架构处理器(Intel/AMD)的底层机器码的文本表示形式。它是操作系统内核、嵌入式系统、逆向工程和性能极致优化领域的核心工具。
1 CPU模型
CPU概述
CPU也叫中央处理单元,是词组Central Processing
Unit的缩写,是计算机系统的核心部件。
计算机系统中绝大多数的设备,都需要CPU的协助才能发挥作用。
是计算机系统的灵魂之所在,无法或缺,难以代替。
早在十八世纪,查尔斯·巴贝奇就设计了CPU的原型------差分机和分析机。

查尔斯·巴贝奇




机械计算机
这个机器有输入设备和输出设备,还可以编程。他的学生奥古斯塔·阿达·拜伦·金为这个机器设计了全世界第一个计算机算法程序------用来计算斐波那契数列。阿达(Ada)也是计算机世界中阿达语言(美国国防部研发的计算机语言,曾经风靡一时,制霸时代)的意思。阿达不仅仅只是写了一个算法,还提出了程序、循环、递归这些基本概念。此外,她在当时还预言计算机可以用符号来描述任何事物,并应用到绘图、音乐和其他科学领域;并且推动分析机从十进制改为二进制。可惜因为癌症,她英年早逝,仅仅活到了36岁,和她的父亲大诗人拜伦一样。

现代意义上的CPU,则是一百多年后,Intel公司开发的4004

虽然在这款产品之前也有一些CPU
但是那个时候的其他计算机是将计算器和控制器分离的
即使这个革命性的4004,它的寄存器(4003)也是一个独立的部件
另外还要配合上4002(只读存储器ROM)和4001(动态内存DRAM)
才能构成一个完整的计算机系统。
但是从这之后,计算机系统就开始了按照摩尔定律高速发展的轨道,一发不可收拾。
现在的CPU虽然和两百年前的分析机或者早期的CPU,形式上已经相去甚远,但是很多机制还是保留了下来。
首先是大家都是采用了二进制;其次是其计算过程差距并不大。
都是输入数据、计算、输出数据,
区别在于,以前是用的机器和纸带完成这些步骤,而现代采取的是电磁来完成这些步骤。
此外,寄存器、内存被分离开了,同时寄存器被集成进入了CPU之中,成为了CPU中一个重要的核心部件。
工作原理
CPU是如何工作的?

这是一张8086CPU的解剖图
比较复杂,那我们换一个简单点的
这是一张嵌入式CPU的电路图。
相较于PC机的CPU,嵌入式的CPU已经简单了几百倍,但是看上去仍然让人感觉头皮发麻。
所以我们还必须继续简化
下面是一张CPU内部的结构图
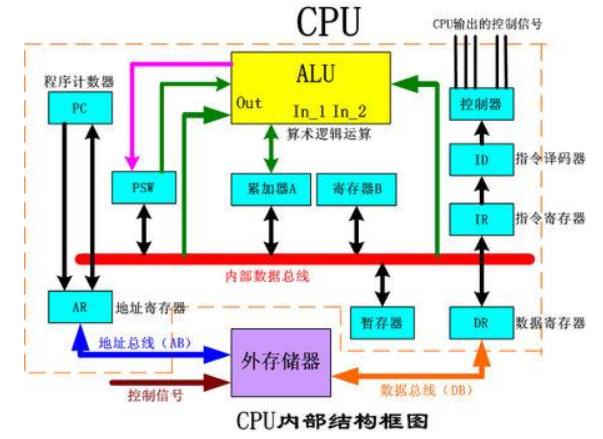
其中PSW叫做程序状态字,所谓的内部总线,大家可以简单理解为一个数据传送带。
关于总线,后面有章节会细说原理和作用。
这个仍然比较复杂,我们再简化一下
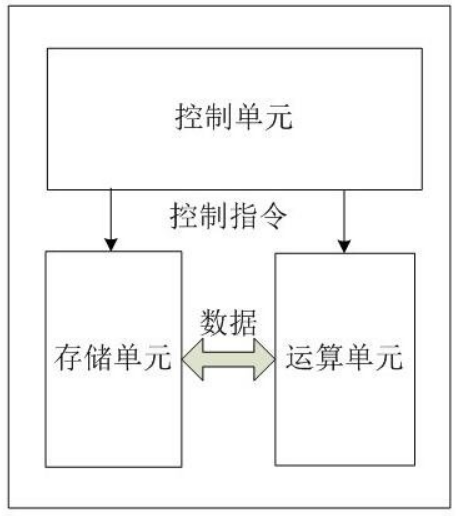
CPU内部,可以简单按照上面这个来理解
CPU和内存一起工作的时候,可以简单表示为下图
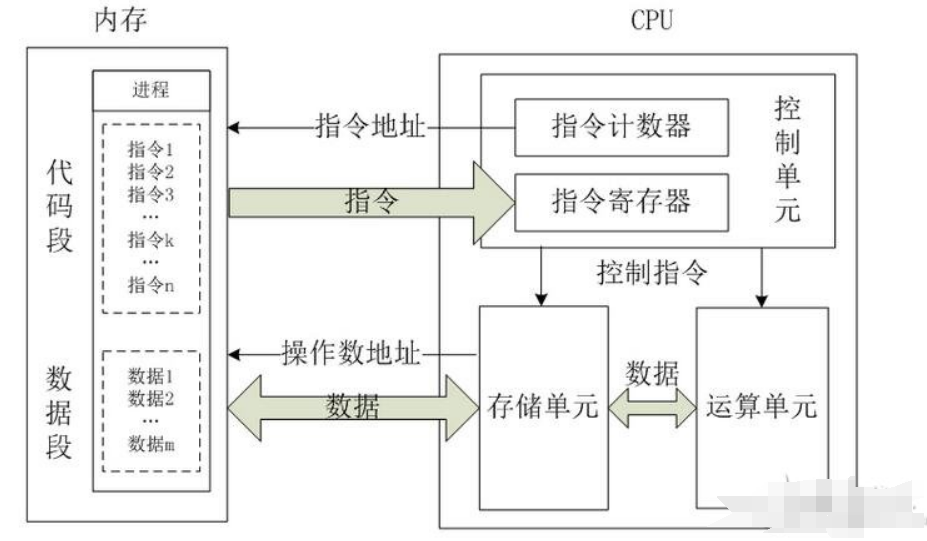
由于CPU硬件的这种情况
所以一般CPU的指令都是这样的格式
操作码 操作数或者操作数地址
这也是为什么寻址这个概念在汇编中那么重要
因为运算所需要的数据都是从不同地址的内存或者存储单元里面来的
没有寻址,就无法找到这些数据,也就无从谈计算了。
寄存器
这个部件以前并不属于CPU,是从8086开始,这个部件才融入CPU之中的。
由于在64位的竞争之中,Intel输给了AMD,
所以大家会发现64位CPU寄存器和32位CPU的寄存器差异巨大。
有多大呢,有图有真相
这个是16位CPU的寄存器
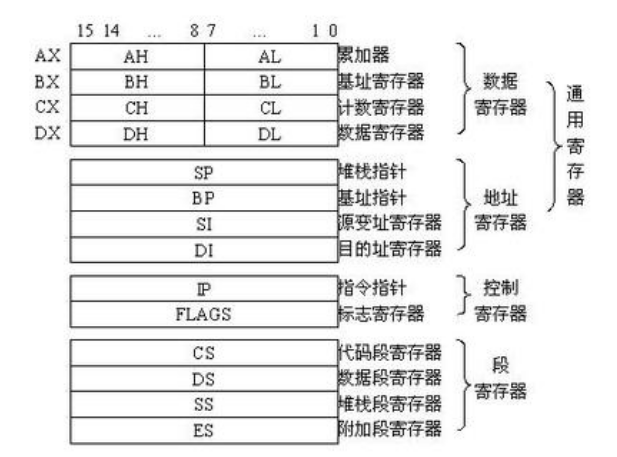
这个是32位CPU的寄存器
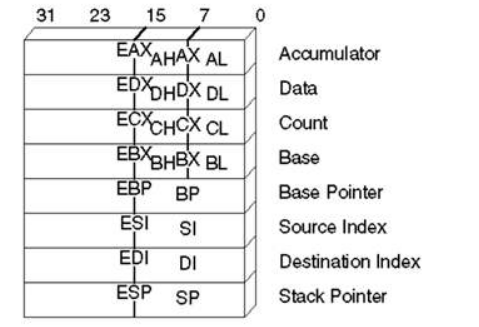
下面是64位CPU的寄存器
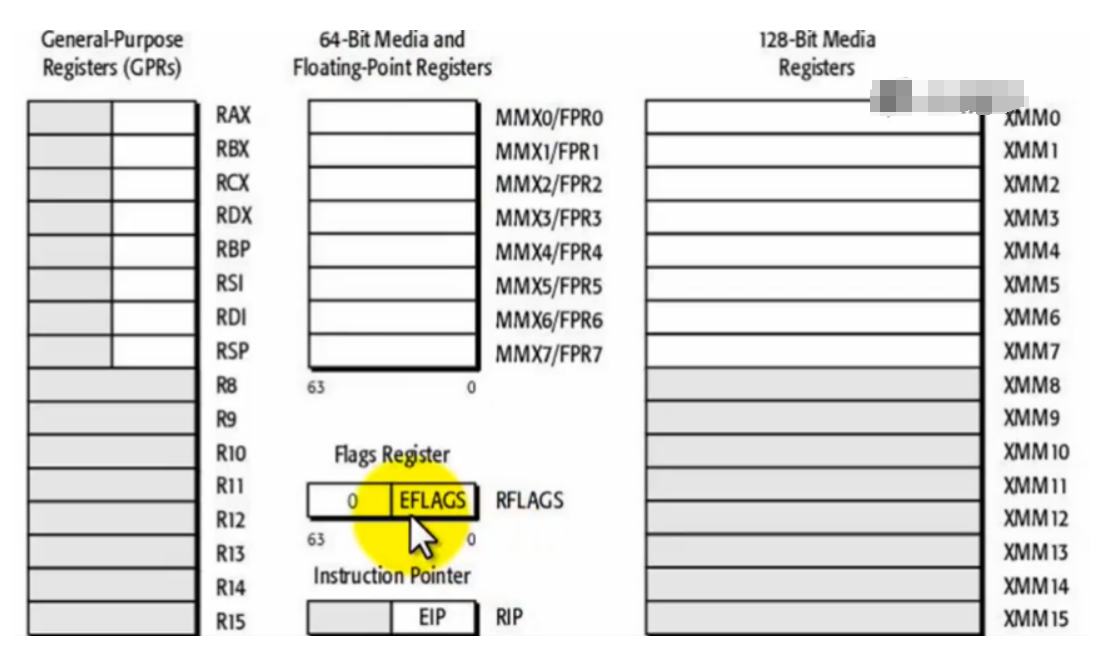
我们可以很清晰的看到,从16位到32位,寄存器几乎只是单纯的把位宽升了一级
但是从32位到64位,几乎就是换了一个系统一样
不仅仅多了很多mmx和fpr寄存器,还有xmm寄存器
同时通用寄存器数量也多了一倍
从原来的八个,直接变成16个
完全是换了一个CPU
不仅如此,对应的编译器也需要更换。
在计算机编译的时候,32位之前的,使用的是同一个编译器
64位的,则是使用的另一个新的编译器
为什么64位x86的CPU会多出来这么多寄存器
这个就不得不提到CPU里面崛起的另一种CPU:ARM
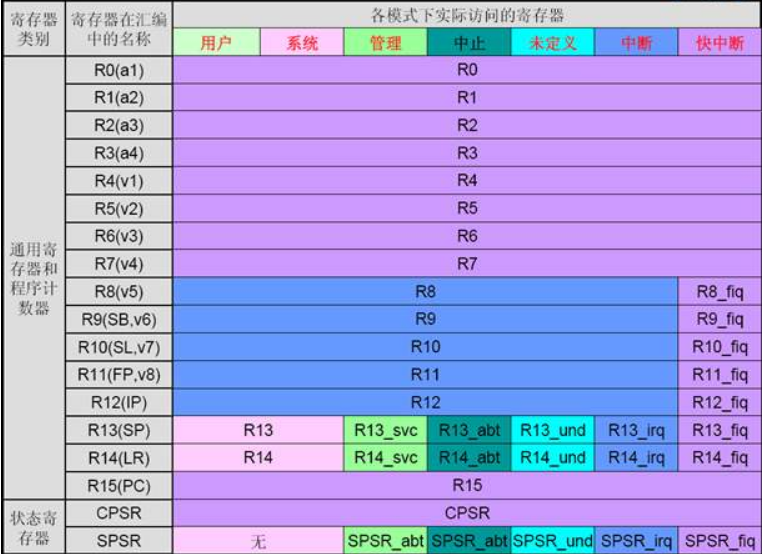
这是一个arm的寄存器示例图
我们明显可以看出来,x64的寄存器和arm的寄存器非常的神似。
在32位时代,通过测试表明,同样频率的芯片,arm架构的计算效率要远高于Intel的x86架构,同时ARM能耗还更低。
为什么呢?这就要从程序执行的一个特点讲起了
程序代码之中,存在大量的函数调用;而有函数调用,往往伴随着参数的传递。
传统的x86传递参数,是通过栈来传递的。
这个在当时没有什么问题。
当时栈是在内存的,而数据从内存到CPU是需要消耗比较多的时间的
虽然现在的CPU有了多级缓存,但是缓存大小还是非常小的
函数调用比较多,且比较频繁的时候,这点就不可避免的影响到CPU的执行效率了
而arm这种CPU,有16个寄存器,哪怕有一些是专用的,其寄存器数量也远超x86
它可以让四个参数以下的函数,无需栈,直接使用寄存器就可以传递。
而这种函数往往也是函数当中的大多数
寄存器传递参数的好处就在于,CPU在计算的时候,没有必要等待内存
直接就在寄存器里面整,而且从一定程度上减少了压栈的操作
极大的提高了函数调用的效率
寄存器的最主要作用就是给CPU的计算单元提供数据存储服务
由于CPU的计算速度非常快,用高速内存和高速缓存都无法解决
计算速度和存取速度的差距
所以寄存器是非常重要的一个部件
也许有的同学会有疑问
那寄存器和内存之间的数据交换就不需要解决类似的问题了吗?
其实寄存器从内存读写数据,也存在类似的问题
这就涉及到现代计算机系统的另外一个创新:指令流水线
指令流水线
什么是指令流水线?
简单的说,就是将指令的执行过程分割为多个步骤
然后通过追加硬件的冗余,让指令仿佛流水线上的产品一样被执行
下面有一个简单的示例:
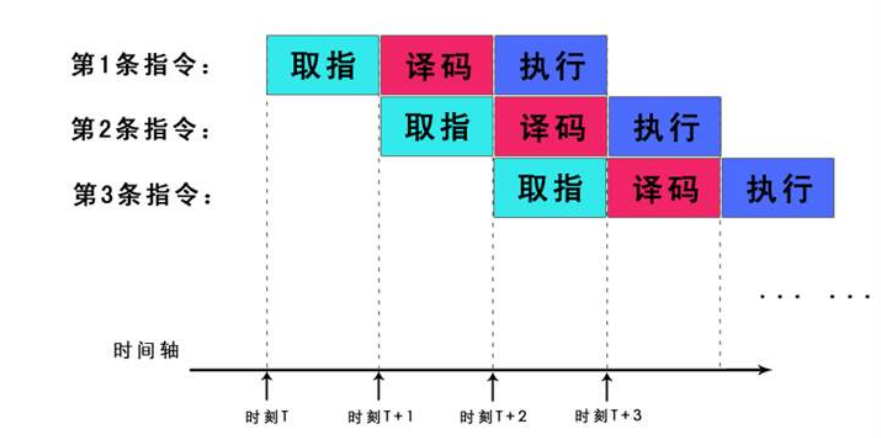
假如我们将一条指令分成三个步骤:取指令、翻译指令、执行指令
那么一条指令我们可以按照上图那样执行
第一条指令在执行的时候,第二条则开始译码,第三条则进行取指令
这样,原本要三个周期的指令,在指令流水线上,平均只需要一个周期
就可以执行完成了
实际使用中的系统里,CPU的指令被分割为最多二十多个步骤
早期的CPU指令也有七个步骤之多
远比我们这里展示的过程要多几倍
这里也可以回答我们上一节提出的问题:寄存器和内存之间的读写速度差异是如何解决的
假如寄存器需要的数据是在执行阶段需要使用的
那么在取址的时候,CPU就可以通知寄存器开始加载数据了
等到执行的时候,已经是第三个周期,中间已经间隔了一个周期
只要寄存器加载的动作能在两个周期内完成,就不会影响最后的执行效率
再配合上多级缓存,内存的读写速度和CPU寄存器的读写速度差距
就可以弥合上了。
但是这里也有一个新的问题出来了
内存是如何与CPU交互数据的?
这就涉及到一个新的问题:内存的工作模型
2 内存工作模型
内存的工作模型是为了解决一个问题:
如何帮助软件开发人员理解内存的运行机制
进而解决软件运行过程中遇到的各种实际问题
这是一块内存条

计算机启动的时候,会把程序从硬盘或者其他存储设备加载到内存。
理论上最好的内存就是CPU的缓存,读写速度快,是内存速率的几倍
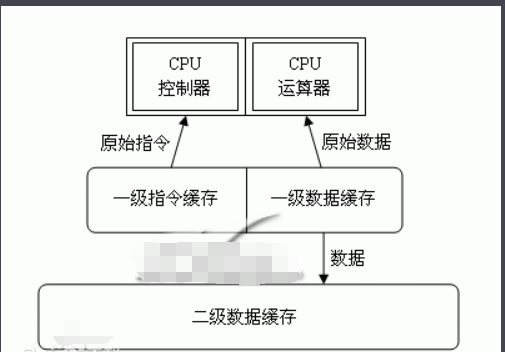
但是实际情况是,CPU的缓存结构复杂、成本高昂、容量也很小
无法大规模应用
所以就只能用一点点
而且缓存还会分为多个级别
每个级别之间的读写速度都有差距,容量也是递减的
现在的多核CPU还会给每个核都配备一个缓存
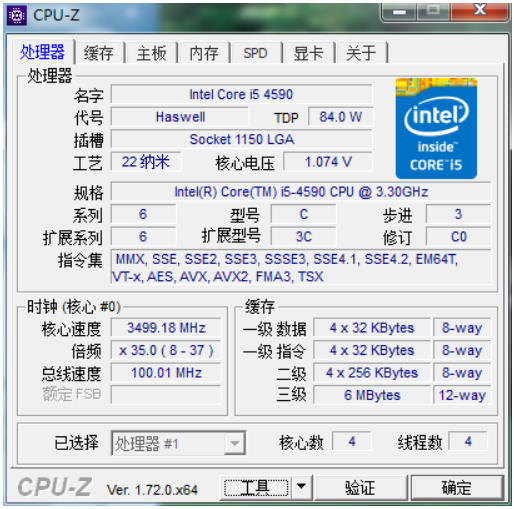
上面是一个i5CPU的参数
CPU的频率是3.5G,一级缓存是128k
同时分为指令缓存和数据缓存
二级是1M,三级就变成6M了
目前CPU的算法,可以让缓存的命中率达到90%
这也意味着,CPU在运行的时候,九成的情况下,不需要去和内存条直接打交道
而是读取缓存就可以了
这让CPU的执行效率也提升不少
内存是如何工作的
内存的工作方式要分为两个方向来讲
一个是内存是如何从外部加载数据的
另一个是内存是如何将数据输出的
但是不论是哪个,其原理如下:
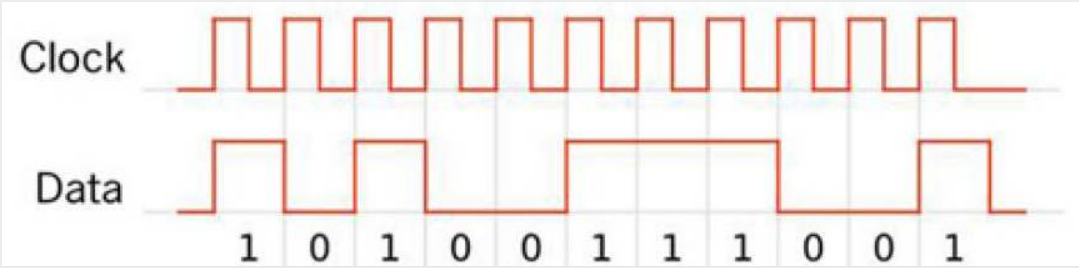
计算机里面有一个晶振部件,会产生周期性的方波
通过修改这个电波,计算机可以在不同部件之间传输数据
所以这个频率越高,意味着单位时间内,可以传输的数据也就越多
但是实际工作的时候,内存的频率往往也会受到主板的限制
并不是无限拔高的
所以有这样的情况,一块高频率的内存条,因为主板配置低
结果只能降频来适配主板,使得整体上性能没有任何提升
内存在系统中的角色和作用
内存是计算机启动时自检的关键部件之一,另外还有CPU
起作用至关重要,绝大部分的计算机系统,如果发现内存错误
是无法运行下去的
其原因就在于,CPU对其他外设的控制,通通都是通过内存来实现的
我们的键盘在内存中有映射
显示器也有显存映射
硬盘、声卡、网卡、风扇等等设备都在内存有映射
所谓有映射,是指这些设备的数据,并不会直接给到CPU
而是先给到内存的规定位置
然后CPU才能去读取的
如果CPU是大脑的话,内存就是神经
离开了大脑,光有神经系统是没有任何用途的
同样,光有大脑,而没有神经系统的话
一样也没有办法动弹,只能是一个无用之物
内存地址的概念
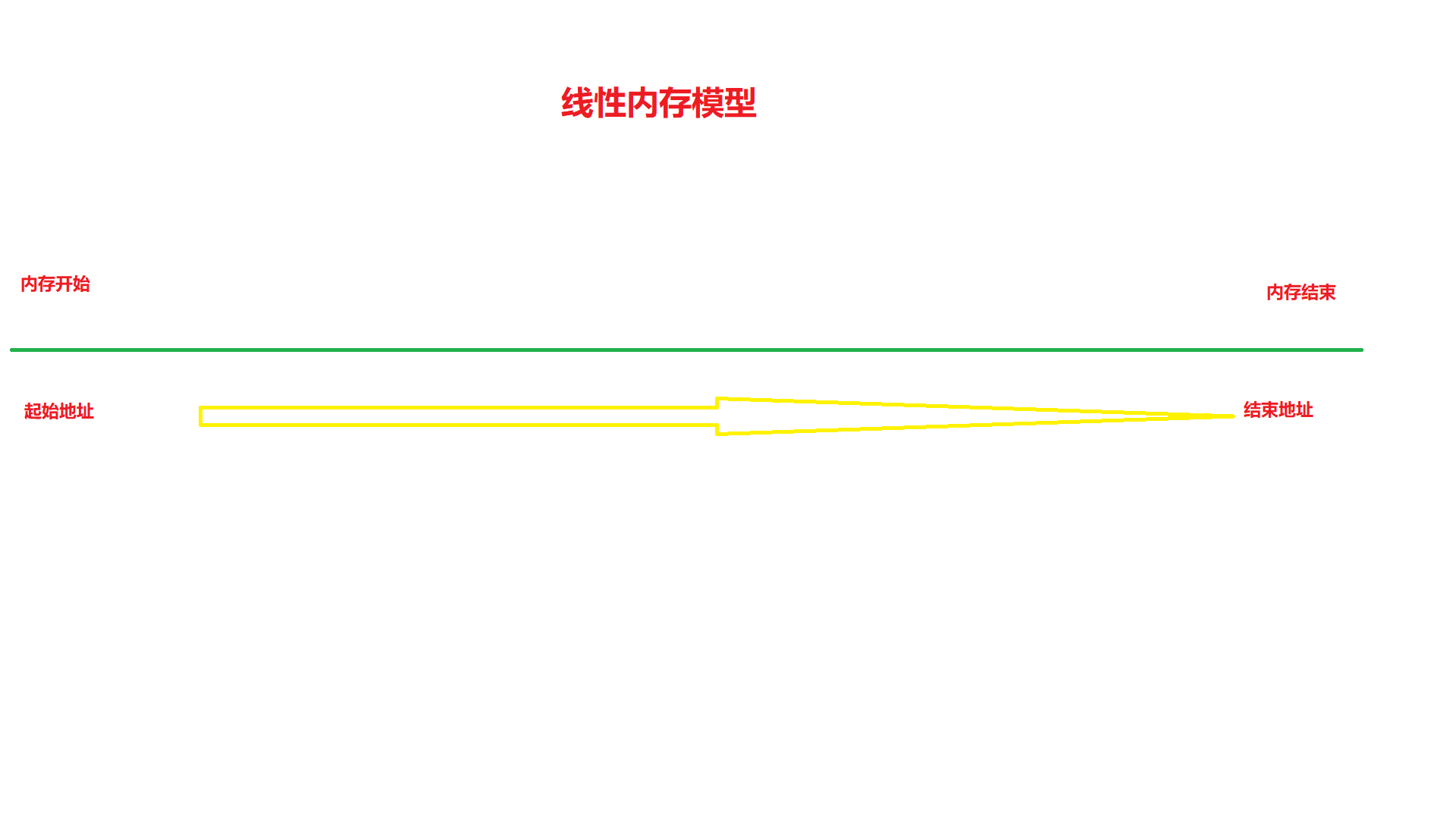
目前我们所有的内存,都是采用的线性内存模型
这意味着内存是一个以字节为单位的,连续紧密排布的存储空间
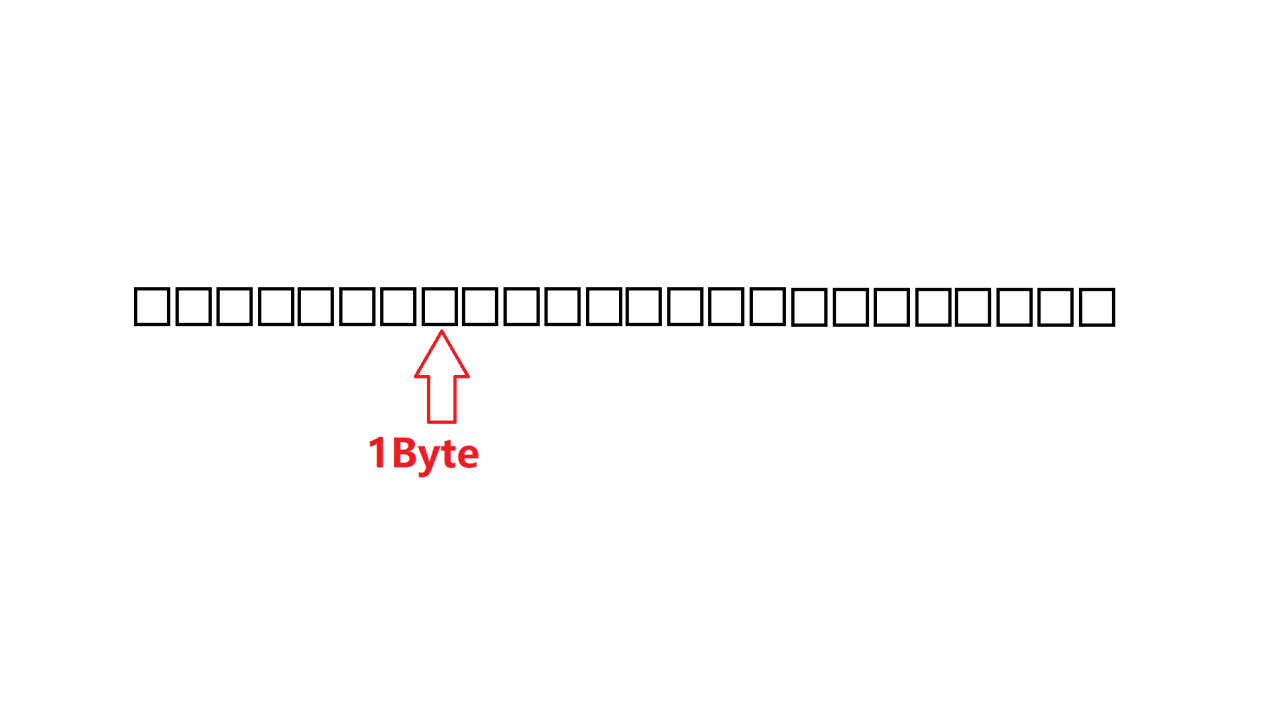
每一个字节都在内存当中,存在一个唯一的地址
这也就是说,地址相同的情况下,我们会操作同一个内存单元
内存单元的编号就是其地址值
为了表达地址,一般使用一个无符号整数来表达
所以,在16位系统中,地址的范围是0~65535(64K)
后面内存容量上去了,为了支持更大的内存容量,所以在x86系统中
出现了一个段寄存器,使得内存访问地址可以达到4,294,967,295(4G)
而这个内存访问量也是早期window的内存管理极限(xp之前的系统)
等到32位系统出现了,地址的范围一开始就是0~4,294,967,295
所以这个阶段,段寄存器就处于半瘫痪状态,几乎没有什么用途
而现在64位几乎完全普及了,地址范围直接都到了0~18,446,744,073,709,551,615(16E)
1E=1024P
1P=1024T
1T=1024G
1G=1024M
1M=1024K
1K=1024bytes
1bytes=8bit
当然这个只是理论值
实际情况是,企业版的64位window也只能管理192G的内存
超过的内存,将无法使用,进而被闲置
而Linux内核可以管理的内存可以达到64T
这也是为什么很多大型服务器,超级计算机都是使用的Linux系统
从来没有window超级计算机的原因之一
此外,为了兼容旧版的程序,64bit的地址真正起作用的,只有48bit
这样干是因为内存太大了,无法像以前16位那样精细化管理
所以,只能拿12bit做页地址,36bit做段地址
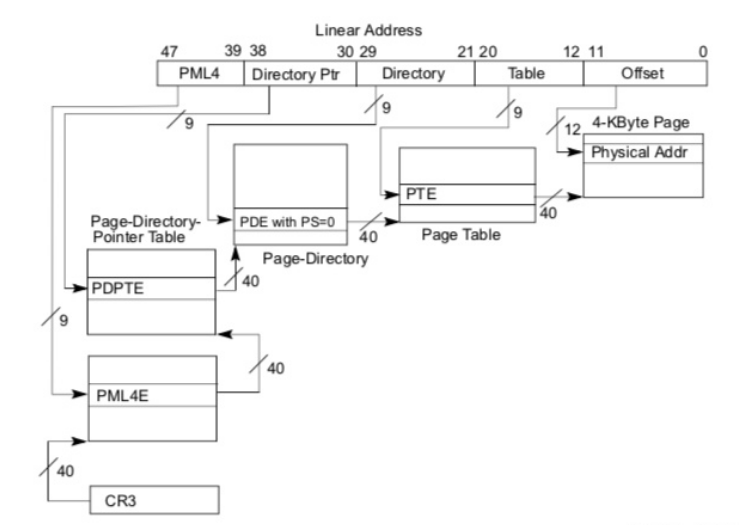
36bit每9bit一组,分成4组,仿佛一个4级目录一般,管理着内存
3 总线的作用
前面我们学习了什么是CPU,什么是内存,但是有一个问题一直没有讲清楚:
CPU和内存之间的数据是怎么传递的?
或者说
数据是如何在计算机的各个部件之间传输的?
这一节我们就来说明这个问题
总线概述
总线是计算机各个部件之间传送信息的公共通信干线
总线不仅仅存在于主板上,还存在于各个部件内部
比如CPU内部也有一条总线,用于寄存器、计算单元、控制单元和缓存之间的数据传递
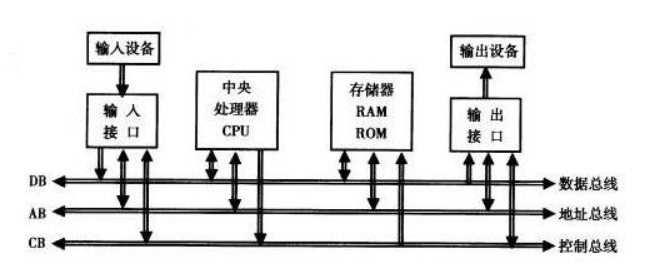
一般总线分为三类:数据总线DataBus、地址总线AddressBus、控制总线ControlBus
对于一些低端的设备,比如输入、输出设备,往往都是等待总线的状态
比如我们在键盘上面敲击一个按键
这个按键输入不会立刻输入到计算机系统中去
而是进入到键盘的缓存,然后等待系统的接入
所以我们会发现,系统卡的时候,按键就没有反应了
正常情况下,系统会在毫秒级的时间内给予响应
所以我们会毫无卡顿感
但是一旦有大量高端的处理正在忙的时候,我们就会感觉很卡
有可能就是键盘的输入无法拿到总线访问权限
总线的优点在于,可以在任意两个总线上的设备之间传递数据
缺点也比较明显,总线上一次只能有一对设备能进行数据传递
这个时候,其他设备只能等待
总线在系统中的作用
真实的系统之中,总线其实无处不在,而且往往会分级
就如同下图:
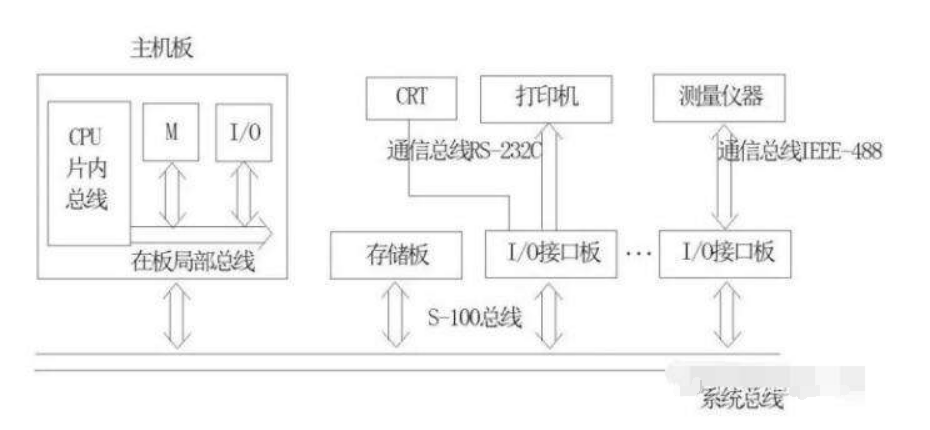
主板的CPU、内存条和显卡之间有一个局部总线,通常是北桥芯片负责
而主板和其他设备之间也有另外一个总线,通常是南桥芯片负责

北桥靠近CPU
南桥靠近硬盘
南桥的内部频率一般要低,北桥的内部频率要高很多
前面讲内存的时候,我们说过,内存数据是如何传出和写入的
而总线就是这个电波的载体
总线本身有不同的频率,通过这些频率,会产生周期的方波
然后通过修改这些方波的电平,我们就可以将数据传输到总线上的各个部件
但是这里要注意
一旦一个部件接入总线,哪怕你不是数据的发起者和接收者,你也会收到这些数据
所以总线在发起和接收之前,需要给各个部件进行编号
然后在发起传输的时候,指明接收的部件,再附带上数据内容
否则所有部件都在总线上,不指明目标,大家都会乱套的
4 硬盘工作模型
硬盘是如何工作的
这是一块机械硬盘

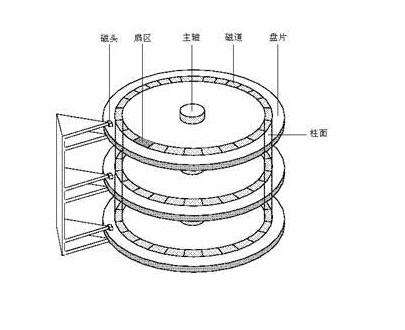
打开盖子之后,里面是这样的

里面各个部件的名称和作用如下图:

一般我们会把这个设备内部结构描述为下面的模型
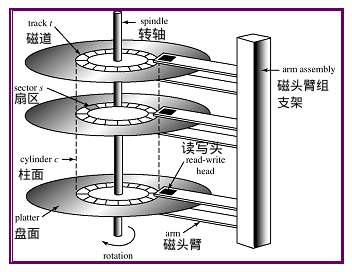
每一个盘面描述为下面的模型:
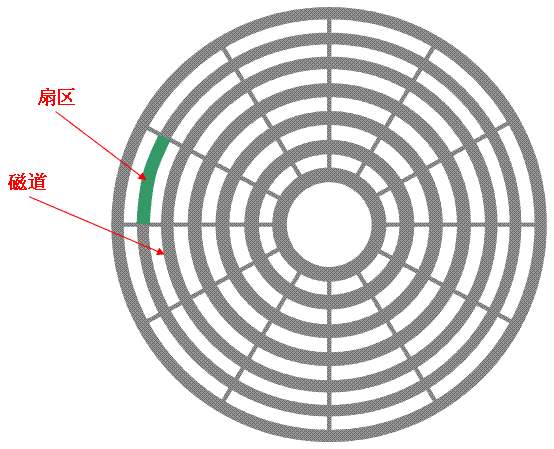
整体的模型如下:
磁头是不动的,所以盘片转的越快,读写速度就会越高
目前市面上多数为7200转的机械硬盘
少数高端硬盘可以达到上万转
盘片不断的转,磁头是可以伸缩的
所以各个磁道都可以读到
由于盘片很薄,转速很高,为了磁头能够很好的工作
必须要把盘片的振动控制到一个很小的范围
否则一旦真的碰触到磁头,对应的磁道就会损毁
这也是为什么笔记本最好不要使用机械硬盘的原因
机械硬盘发生撞击、掉落,容易损坏也是这个原因
内存读写速度和硬盘读写速度的对比
硬盘写入速度测试命令:
dd if=/dev/zero of=file bs=1M count=1024

硬盘读取速度测试命令:
dd if=file of=/dev/null bs=1M count=1024

内存读写速度测试命令:
dd if=/dev/zero of=/dev/null bs=1M count=1024

通过这个测试,我们可以看到,内存的写入速度是硬盘写入速度的60多倍
这么巨大的读写速度差距,我们可以明显的感觉出差异来
硬盘写入1个G的时候,要花费6、7秒
而内存读写1个G只花费了0.1秒左右
此外硬盘的读取速度明显要比写入速度快很多,可以达到3.7GB/s
是写入速度的20多倍
所以硬盘写入慢,读取快
此外内存读写也有速度差异,连续读取和随机读取也有速度差异
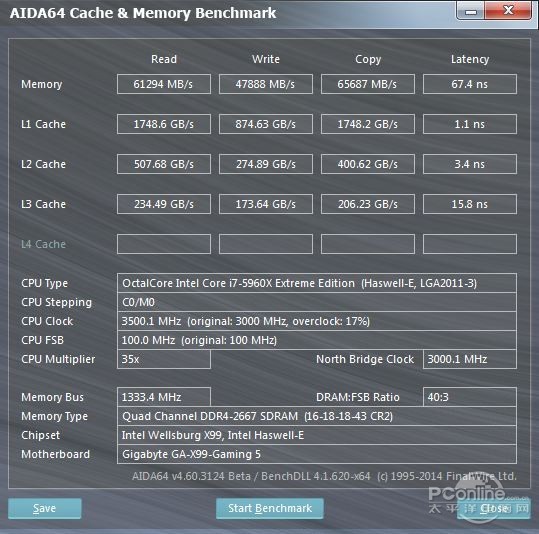
上面这张是内存和各个缓存的测试结果图
我们可以看到一级缓存L1 Cache速度最高,
达到了恐怖的1.7T/s的读取速度和874G/s的写入速度
后面的缓存逐级递减,同时容量逐级递增
这个是频率为1333的内存条,明显比我的内存要差一截
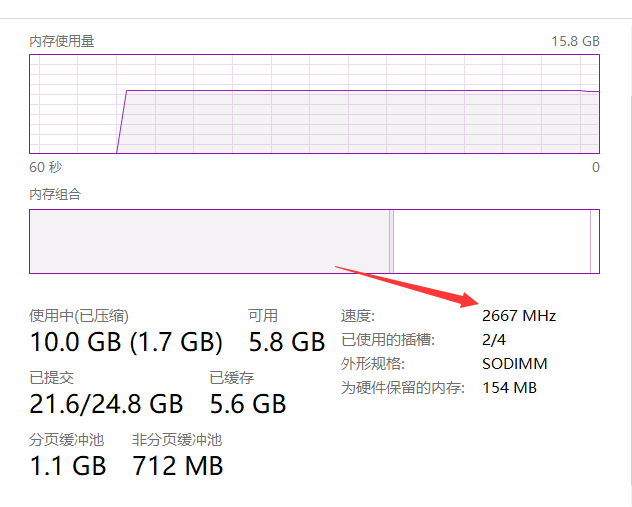
我的机器频率是2666的,是上面的一倍
传输速度提高了66%
所以内存频率越高,读写速度越快,对应的系统运行速率也越高。
5 显卡工作模型
前面我们讲过,在北桥芯片上,和CPU、内存条在一起的,还有一个显卡

CPU、显卡、主板和内存条是个人计算机系统中的四大恶人
各个都是吞金兽,烧钱怪。其中显卡在其中尤为突出
很多追求显示性能的人,显卡的花费甚至比CPU还要高
所以搞清楚显卡的工作原理,我们才能明白钱是怎么花出去的
最后才能为自己的奢侈找到一个技术理由
显卡是如何工作的
早期的显卡主要协助CPU处理数字图像的
比如一张1920*1080的图片

当最终显示的时候,会占用1920*1080*4字节的显示空间
一共有超过两百万个点,八百多万个字节
但我们想对其进行一些处理,比如:淡入淡出、旋转、翻转等变化的时候
这些点的处理就会比较棘手
单单只是做两百万的空循环,对于CPU来说,都是一个不小的开销
因为每次循环,CPU需要执行五条以上的指令
两百万次循环,需要千万次的计算
如果加上点的颜色处理计算,计算量轻轻松松过亿次
如果一张图片的处理就要消耗大量的CPU计算时间
那么对于需要处理大量图片的游戏来说
CPU就可以原地爆炸了

为什么,因为游戏每秒至少要处理24张以上的图片,才能让人感觉画面是连续的
要60张以上,才能让人觉得画面非常流畅
也就是说42ms处理一张图片,才能让人觉得你不是在放PPT
速度达到16.7ms处理一张图片,才能让人觉得画面流畅
而现在的游戏,动不动都是120帧,甚至240帧
这意味着速度要达到8ms乃至4ms一帧,才能算是高水准的画面
这需要每秒240亿次,甚至更高的运算力
如果是3D游戏,画面运算的算力需求还要翻上十几倍
所以为了降低游戏对算力的要求

早期的3D游戏,模型都非常粗糙
基本上都是几个平面模型的拼接加上一些纹理的渲染来搞定
等到现在,由于显卡技术的不断提升

尤其是光线追踪技术的应用
3D模型的效果差距简直就是一个地一个天
那么显卡为什么能够帮到CPU呢?
回到图片处理的原始需求上来
图片的处理,其实可以看成大量的整数运算
因为点都是按照三原色值保存的,每个颜色的值从0到255
一共可以表达一千六百多万种颜色,这就是所谓的真色彩
这是一个显卡的参数列表
显卡有自己的显存和计算单元
和CPU少的可怜的计算核心不同
显卡的计算核心,现在动不动都是好几千,甚至上万
图片计算往往都是大量同性质运算
所以可以控制大量的计算单元来协同计算
实际工作的时候,CPU会先把素材从内存加载到显存
然后通过显卡指令控制GPU开始预设好的计算
最后将显存中的数据投放到显示器,以进行显示
显存是如何工作的
这是一块早期的英伟达显卡

图中黄色方框内的器件,就是显存
现在的显卡已经很少会这么将显存暴露在外部了
一般都被散热板或者风扇给遮盖住了
在图形图像处理的过程中,会涉及材质、纹理、光照和坐标等四个基本处理
每一个处理过程都会产生一些结果
其中很多结果都不是最终显示的结果
但是作为中间过程,可以保留下来
为后面的计算和处理作准备
显存的数据是通过内存传递过来的
但是显存数据最终不一定需要传回到内存去
而是可以直接输出到显示器上
显存有几个关键参数:容量、频率和位宽
容量决定了你可以存储多少素材、纹理
大型游戏启动的时候,往往有一个漫长的加载过程

这个时间往往就是游戏在加载素材、纹理、模型等等
这些东西一般不是加载到内存,而是加载到显存之中
如果显存容量越大,那么可以加载的东西就越多
场景切换的时候,需要重新加载新素材的时间就越少
进而游戏体验就会更流畅
速度则主要是由频率来决定的
注意显存和内存不是一个概念
所以显存频率也无法与内存频率进行直接比较
速度显然是越快越好
越快写入和读取会越流畅
最后是位宽,位宽是只一次能处理的bit位数量
有时候频率高但是位宽低的显卡,其表现还不如频率低但是位宽高的显卡
因为位宽决定了数据出入口的大小


如果位宽降低一半,对应的频率需要提高一倍,才能有齐平的表现
6 网卡工作模型
网卡的介绍
网卡现在已经是几乎所有计算机的标配了
就算没有有线网卡,也必然会配一个无线网卡
下图是一个常见的PC端网卡
BootROM是无盘启动ROM的接口,通常用于启动服务,构造无盘工作站的
总线接口是指到南桥的接口

数据泵则一方面是传输数据,二方面是隔离电平和防止雷击
这里的RJ-45接口,就是我们常说的水晶头接口


下图是一个无线网卡

但是现在大部分的无线网卡,做成了usb设备

甚至可以配上电话流量卡,直接使用手机网络

上面都是PC网卡,对于服务器,网卡也有一些变化

首先是网口会更多
这也意味着一台服务器可以拥有更多的地址
实际运行的时候,对于多个网口,会保留一个做内网接口
其他的依据情况,使用不同运营商的不同地址
内网接口用于服务器内部组网,一般是局域网
这种连通率高,连接稳定,延时低,设备可信度高
常常用来将对外的服务器和后台服务器(比如数据库服务器)组织在一起
而其他的外网接口,用于对外提供网络服务
这种接口连通率低,连接不稳定,延时高,设备完全不可信,需要进行认证
光纤和同轴电缆的差异
网卡解决了数据传输的收发问题,但是数据如何在不同设备之间流转
还需要用到网线
网线分为同轴电缆线和光纤线
下图是光纤线


由于光信号的特性,光纤通信的密度要远大于电缆线
这是因为不同频率的光可以合并在同一根光纤上传输
而相互之间不会影响
这点电缆就无法做到

所以光纤线的性能,一般都在千兆级别,而电缆线的传输极限也就是千兆
目前单个频率光波的传输速度可以达到40Gb/s
而且一根光纤可以跑80个频率
使得速度达到3200Gb/s
更厉害的是传输距离还远,可以达到几十公里
但是电缆线,超五类的,最多也就是2Gb/s,距离只有可怜的几百米
下图是一根电缆线的解剖图

下图是一个七类的电缆线,一般用于高速内网的组建

目前国内的网络情况,都是使用光纤组建主网络
终端使用同轴电缆连接其他设备
一方面是同轴电缆在短距离上(100米以内),性能还是可以的
而且制作维护方便,长度可以随意剪裁。
另一方面是光纤线长度难以随意剪裁
而且一旦断了,接续过程非常麻烦,远没有电缆接续方便
网卡的工作原理
现在我们搞清楚了设备是怎么样的
网线是怎么选型的
那么网络数据是如何顺着网线,经过网卡进入内存的呢?
这就要说是网卡的工作原理了
下图清晰的解释了网络数据是如何被用户收到的
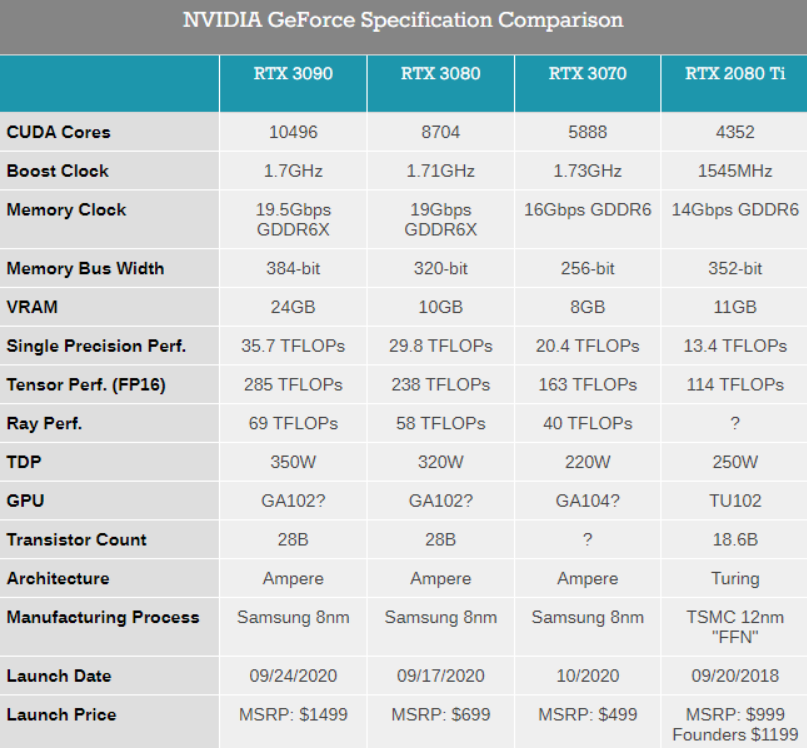
真实数据从物理链路层来
所谓的物理链路层就是网线、路由器、网关这些设备的总称。
数据来了之后,就进入到了物理网卡
物理网卡会通过总线,将数据传输给操作系统准备的内存缓冲区
然后操作系统会处理套接字的状态
发出信号,通知相关程序唤醒线程,或者激活事务
在用户层的程序接到这些信号之后
就会开始读写数据
从而将网络上的数据导入到应用程序的内存中来
可能有的同学看到驱动感觉有点懵
其实驱动就是一套程序
这个程序有标准的接口(或者说对外可以调用的函数)
操作系统可以通过这些接口来访问和控制对应的设备
比如网卡的驱动,

这里面name就是驱动的名称
id_table是一张表
probe是初始化接口(也就是一个初始化函数)
这些接口都是操作系统规定好的函数
其参数和功能,基本都有规定
按照这个实现这些功能后
再配合上硬件
操作系统就可以使用网卡来处理数据了
x86汇编指令
快速搭建一个汇编学习项目
如何创建项目
在Windows下学习汇编是一个艰难且巨大的工程,
对于初学者,尤其是还要自己写一堆意义不明的伪指令
才能将一个程序运行起来,这就更是难上加难了
所以为了降低难度,减少大家的工作量
我们推荐使用按照下面的方法来搭建汇编的的学习和研究环境
首先打开Visual Studio 2019(以下简称VS)

启动后,选择 创建新项目
在项目选择界面,选择 C++控制台项目
在配置新项目界面,按照下面的内容填写好
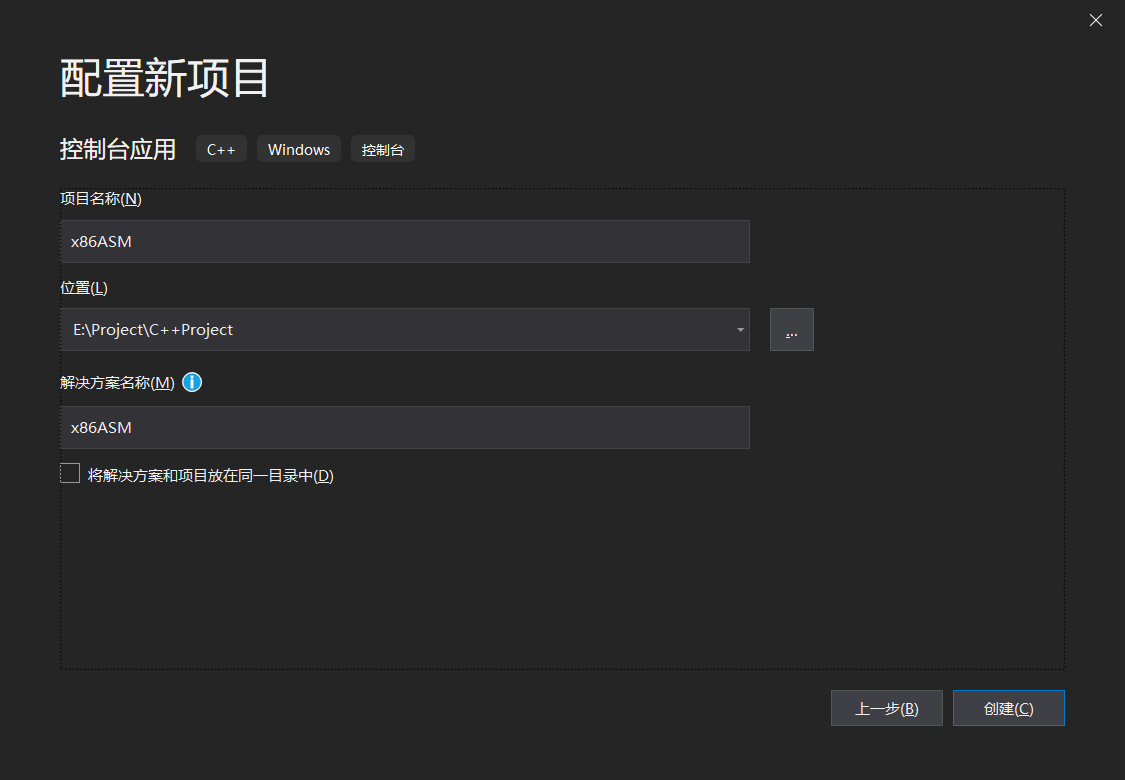
项目创建完成后,确认一下项目的CPU架构是x86
到此,项目创建完毕
如何使用项目
项目创建之后,还是一个C++项目
如何写汇编,并且观察效果呢?
首先我们可以这样写代码:
#include <iostream>
int main()
{
int nEax = 0, nEbx = 0;
std::cout << "Hello World!\n";
__asm {
MOV nEax, eax;
MOV nEbx, ebx;
}
printf("eax = %08X ebx = %08X\r\n", nEax, nEbx);
}
然后设置断点
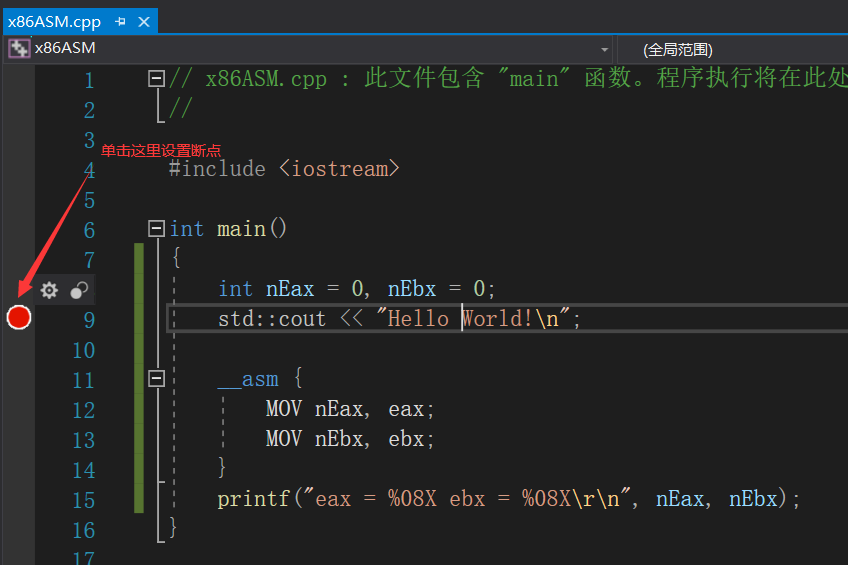
然后按下F5键或者在调试菜单栏选择 开始调试
这个时候会进入调试状态
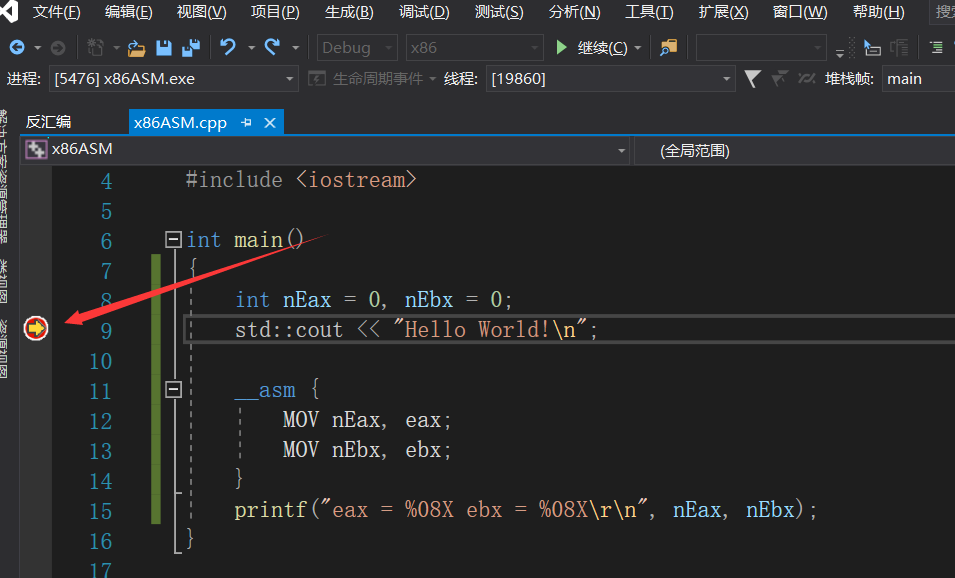
执行一行语句,按下F10
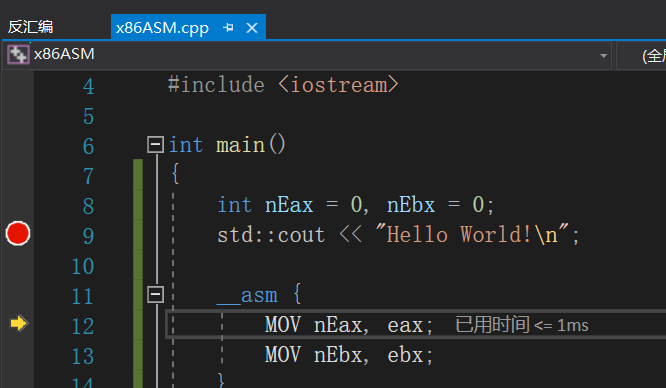
这个时候可以用鼠标右键单击黄色箭头所指向的行
选择转到反汇编
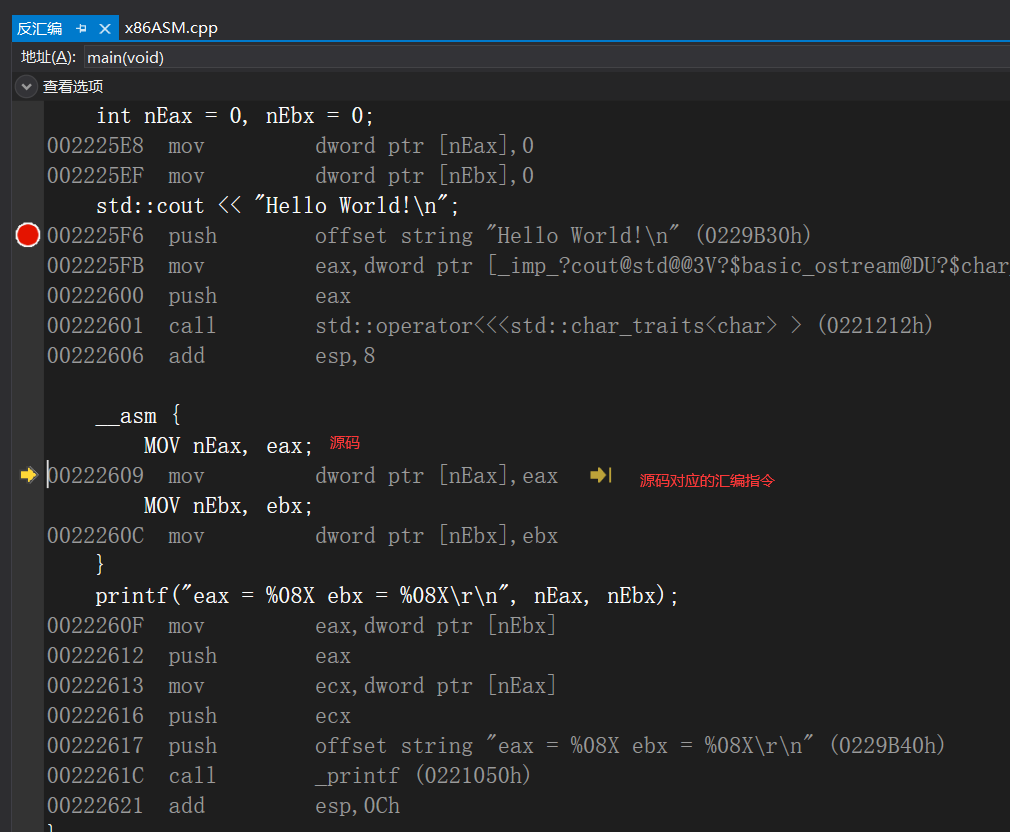
这个时候我们可以看到原始的汇编指令
然后点击下面的监视1
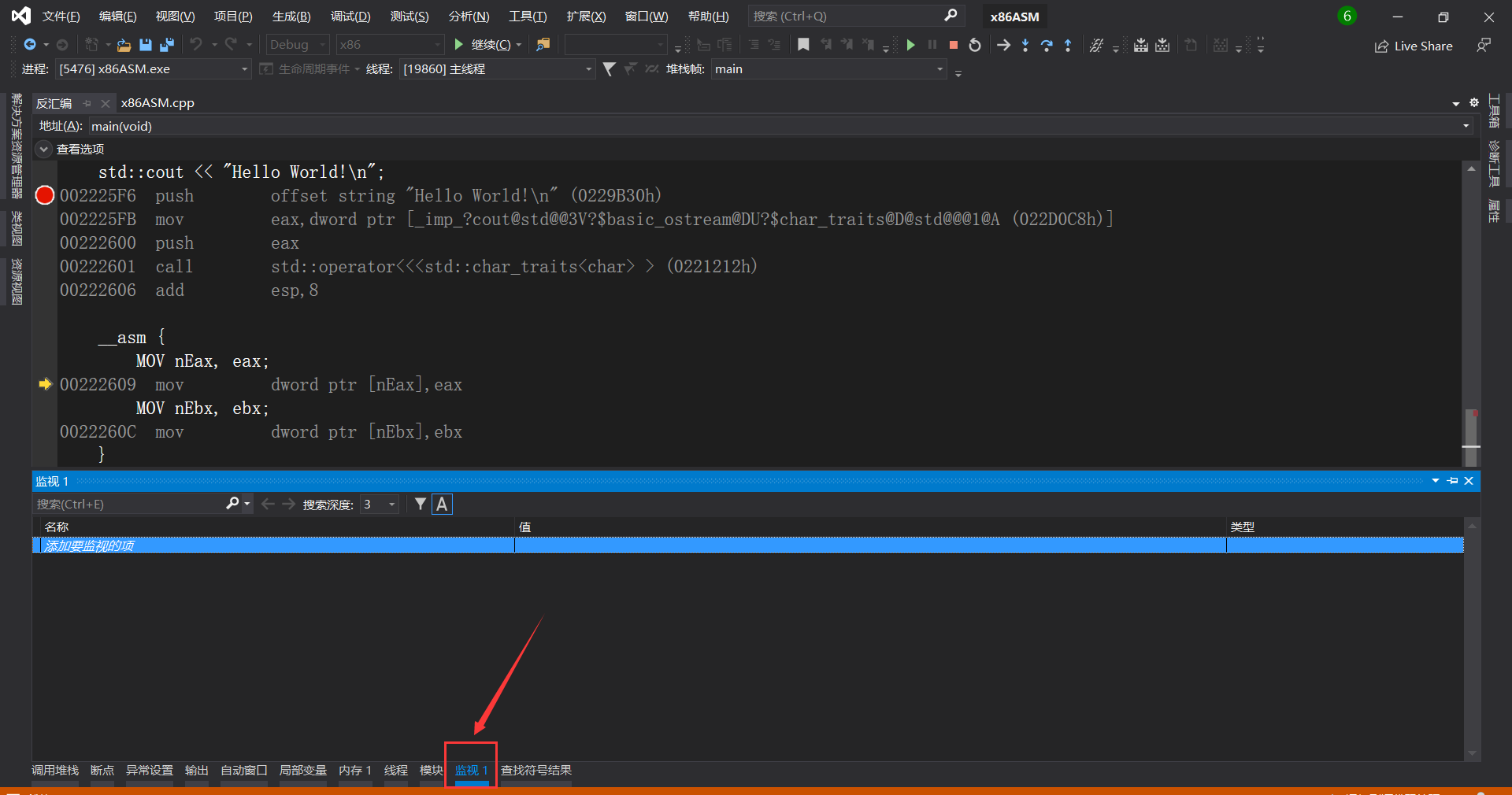
或者在 调试→窗口→监视→监视1~4
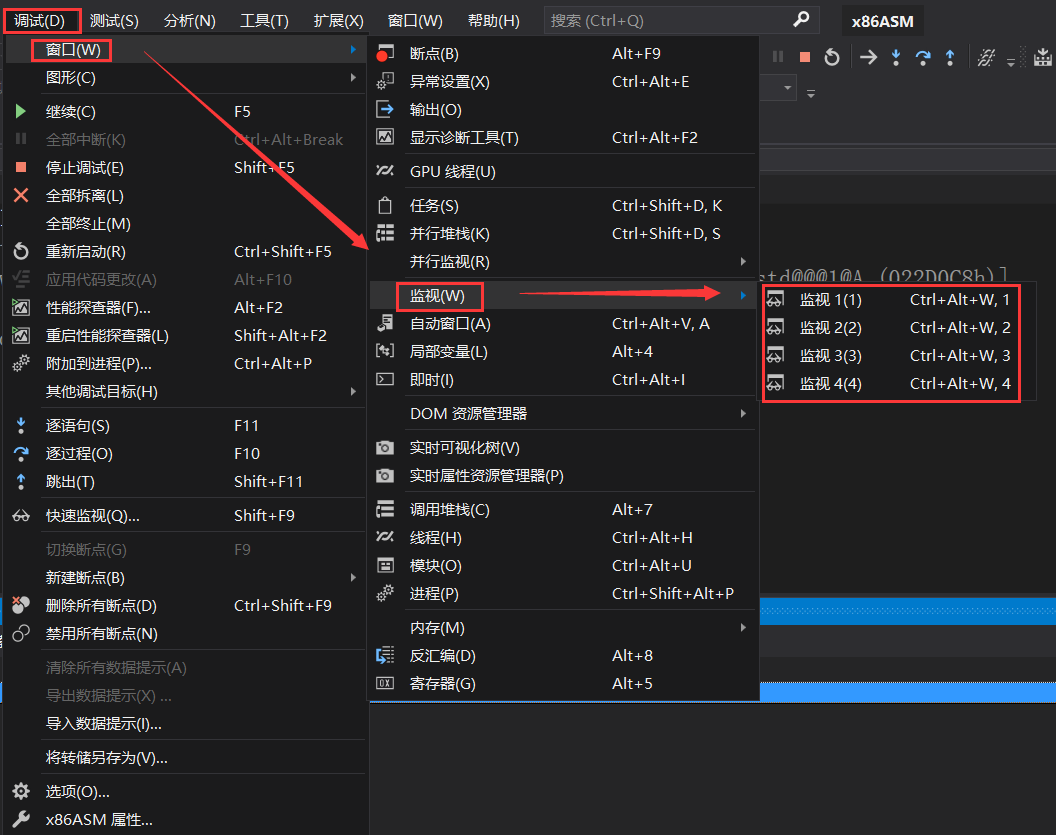
打开监视窗口
输入要监视的内容

可以是寄存器、变量、函数、对象、常量、地址等等
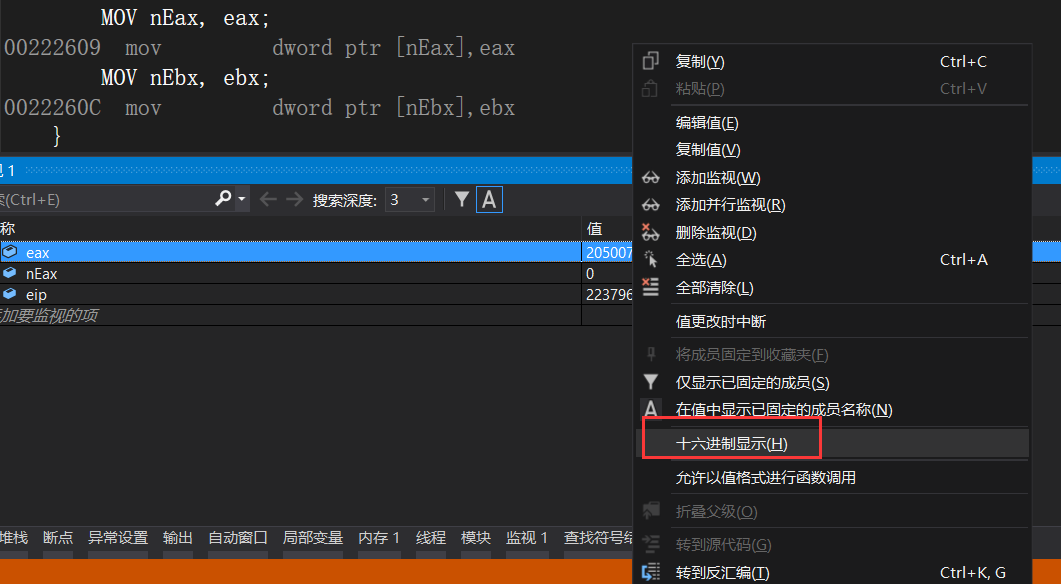
右键单击这个监视栏,可以选择十六进制显示
让其显示十六进制值而不是十进制值
在反汇编页面,选择调试→窗口→寄存器
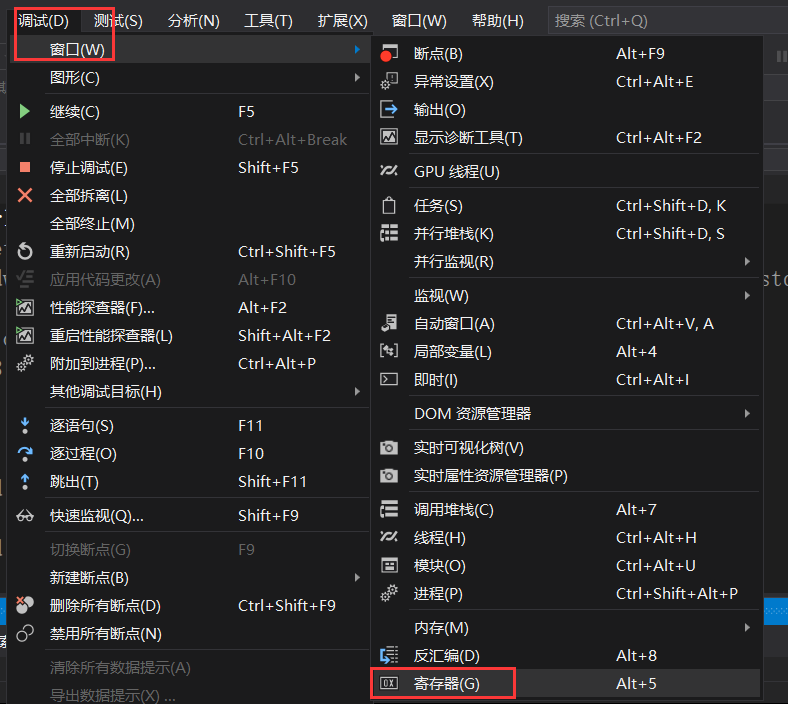
我们可以打开CPU寄存器页面
可以看到各种寄存器的实时值
并且可以选择要查看寄存器的选项
使用这种方式来学习汇编语句
一方面是可以单条语句的学习
另一方面是无需配置CPU、段、对齐等等参数
直接使用C++与汇编混合编程
更利于理解和快速上手
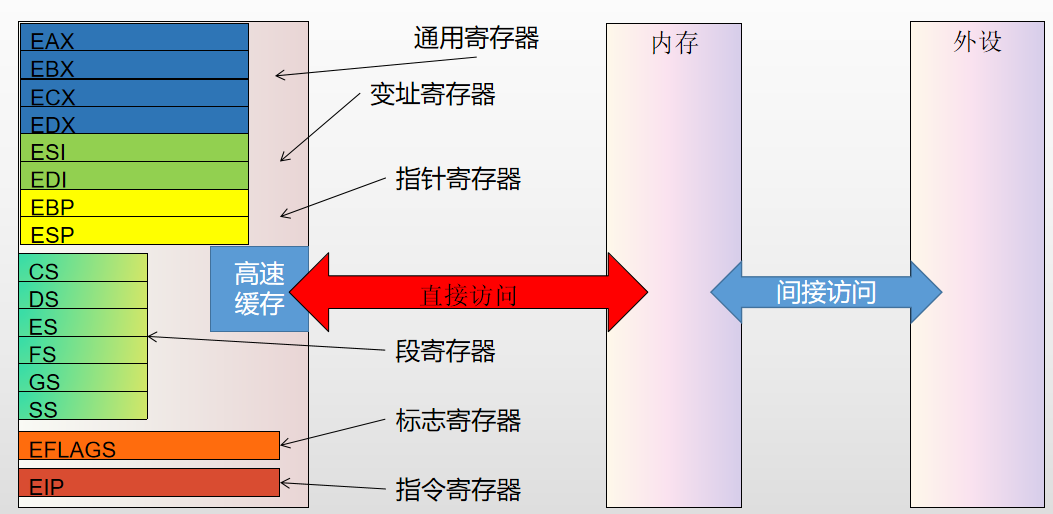
汇编中的寄存器
[8个通用寄存器:EAX、EBX、ECX、EDX、ESI、EDI、ESP、EBP]{.underline}
[1个标志寄存器:EFLAGS]{.underline}
[6个段寄存器:CS、DS、ES、FS、GS、SS]{.underline}
4个控制寄存器:CR0、CR1、CR2、CR3
8个调试寄存器:DR0、DR1、DR2、DR3、DR4、DR5、DR6、DR7
4个系统地址寄存器:GDTR、IDTR、LDTR、TR
其他寄存器:EIP、TSC
通用寄存器
32位 16位 8位
EAX AX AH、AL
EBX BX BH、BL
ECX CX CH、CL
EDX DX DH、DL
ESI SI ** **
EDI DI ** **
ESP SP ** **
EBP BP ** **
EAX:累加器([Accumulator]{.underline}),
它的低16位即是AX,而AX又可分为高8位AH和低8位AL。EAX是很多加法乘法的缺省寄存器,存放函数的返回值,用累加器进行的操作可能需要更少时间,在80386及其以上的微处理器中可以用来存放存储单元的偏移地址。AX寄存器是算术运算的主要寄存器。
EBX:基地址寄存器([Base Register]{.underline}),
它的低16位即是BX,而BX又可分为高8位BH和低8位BL。主要用于在内存寻址时存放基地址。
ECX:计数寄存器([Count
Register]{.underline}),它的低16位即是CX,而CX又可分为高8位CH和低8位CL。在循环和字符串操作时,要用它来控制循环次数;在位操作
中,当移多位时,要用CL来指明移位的位数;是重复(REP)前缀指令和LOOP指令的内定计数器。
EDX:数据寄存器([Data
Register]{.underline}),它的低16位即是DX,而DX又可分为高8位DH和低8位DL。在进行乘、除运算时,它可作为默认的操作数参与运算,也可用于存放I/O的端口地址;且总是被用来放整数除法产生的余数。
ESI/EDI:分别叫做源/目标索引寄存器([Source/Destination Index
Register]{.underline}),它们的低16位分别是SI、DI。它们主要用于存放存储单元在段内的偏移量,用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。在很多字符串操作指令中,
DS:ESI指向源串,而ES:EDI指向目标串。此外,它们又作为通用寄存器可以进行任意的常规的操作,如加减移位或普通的内存间接寻址。
EBP/ESP:分别是基址针寄存器([Base Pointer
Register]{.underline})/堆栈指针寄存器(Stack Pointer
Register),低16位是BP、SP,其内存分别放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶/底部。主要用于存放堆栈内存储单元的偏移量,用它们可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。指针寄存器不可分割成8位寄存器。作为通用寄存器,也可存储算术逻辑运算的操作数和运算结果。并且规定:BP为基指针(Base
Pointer)寄存器,用它可直接存取堆栈中的数据;SP为堆栈指针(Stack
Pointer)寄存器,用它只可访问栈顶。在32位平台上,ESP每次减少4字节。EBP最经常被用作高级语言函数调用的"框架指针"(frame
pointer),EBP
构成了函数的一个框架,在C++反汇编中EBP通常是局部变量、传进来的参数。这里要注意在intel系统中栈是向下生长的(栈越扩大其值越小,堆恰好相反)。在通常情况下ESP是可变的,随着栈的生长而逐渐变小,而ESB寄存器是固定的,只有当函数的调用后,发生入栈操作而改变,在函数执行结束之后需要还原。
标志寄存器

EFLAGS属于状态寄存器,它们对程序地执行至关重要。
EFLAGS:主要用于提供程序的状态及进行相应的控制。32位的EFLAGS寄存器包含一组状态标志、系统标志以及一个控制标志。在x86处理器初始化之后,EFLAGS寄存器的状态值为0000
0002H。第1、3、5、15以及22到31位均被保留,这个寄存器中的有些标志通过使用特殊的通用指令可以直接被修改,但并没有指令能够检查或者修改整个寄存器。通过使用[LAHF/SAHF/PUSHF/POPF/POPFD]{.underline}等指令,可以将EFLAGS寄存器的标志位成组移到程序栈或EAX寄存器,或者从这些设施中将操作后的结果保存到EFLAGS寄存器中。在EFLAGS寄存器的内容被传送到栈或是EAX寄存器后,可以通过位操作指令(BT,BTS,
BTR,
BTC)检查或修改这些标志位。当调用中断或异常处理程序时,处理器将在程序栈上自动保存EFLAGS的状态值。若在中断或异常处理时发生任务切换,那么EFLAGS寄存器的状态将被保存在TSS中,注意是将要被挂起的本次任务的状态。
1、状态标志(Status Flags)
EFLAGS寄存器的状态标志(0、2、4、6、7以及11位)是指示算术指令(如ADD, SUB,
MUL以及DIV指令)的结果,这些状态标志的作用如下:
CF(bit 0) [Carry flag]
若算术操作产生的结果在最高有效位(most-significant
bit)发生进位或借位则将其置1,反之清零。这个标志指示无符号整型运算的溢出状态,这个标志同样在多倍精度运算(multiple-precision
arithmetic)中使用。
PF(bit 2) [Parity flag] 如果结果的最低有效字节(least-significant
byte)包含偶数个1位则该位置1,否则清零。
AF(bit 4) [Adjust flag]
如果算术操作在结果的第3位发生进位或借位则将该标志置1,否则清零。这个标志在BCD(binary-code
decimal)算术运算中被使用。
ZF(bit 6) [Zero flag] 若结果为0则将其置1,反之清零。
SF(bit 7) [Sign flag]
该标志被设置为有符号整型的最高有效位。(0指示结果为正,反之则为负)
OF(bit 11) [Overflow flag]
如果整型结果是较大的正数或较小的负数,并且无法匹配目的操作数时将该位置1,反之清零。这个标志为带符号整型运算指示溢出状态。
溢出OV(overflow,OF=1)
增量UP(direction up,DF=0)
允许中断EI(enable interrupt,IF=1)
正PL(plus,SF=0)
零ZR(zero,ZF=1)
辅助进位AC(auxiliary carry,AF=1)
偶校验PE(even parity,PF=1)
进位CY(carry,CF=1)
在这些状态标志中,只有CF标志能够通过使用STC,
CLC以及CMC指令被直接修改,或者通过位指令(BT, BTS,
BTR以及BTC)将指定的位拷贝至CF标志中。
这些状态标志允许单个的算术操作产生三种不同数据类型的结果:无符号整型,有符号整型以及BCD整型。如果把该结果当做[无符号整型]{.underline},那么CF标志指示越界(out-of-range)状态------即进位或借位,如果被当做[有符号整型]{.underline},则OF标志指示进位或借位,若作为[BCD数]{.underline},那么AF标志指示进位或借位。
SF标志指示有符号整数的符号位,ZF指示结果为零。
此外在执行多倍精度算术运算时,CF标志用来将一次运算过程中带进位的加法(ADC)或带借位的减法(SBB)产生的进位或借位传递到下一次运算过程中。
2、控制标志(DF flag)
DF(bit10)[Direction flag]控制串指令(MOVS, CMPS, SCAS,
LODS以及STOS)。设置DF标志使得串指令自动递减(从高地址向低地址方向处理字符串),清除该标志则使得串指令自动递增。STD以及CLD指令分别用于设置以及清除DF标志。
置1是减,置0是加,ESI/EDI
3、系统标志以及IOPL域(System Flags and IOPL Field)
EFLAGS寄存器中的这部分标志用于控制操作系统或是执行操作,它们不允许被应用程序所修改。这些标志的作用如下:
TF(bit 8) [Trap
flag]将该位设置为1以允许单步调试模式,清零则禁用该模式。
IF(bit 9)[Interrupt enable
flag]该标志用于控制处理器对可屏蔽中断请求(maskable interrupt
requests)的响应。置1以响应可屏蔽中断,反之则禁止可屏蔽中断。
IOPL(bits 12 and 13) [I/O privilege level
field]指示当前运行任务的I/O特权级(I/O privilege
level),正在运行任务的当前特权级(CPL)必须小于或等于I/O特权级才能允许访问I/O地址空间。这个域只能在CPL为0时才能通过POPF以及IRET指令修改。
NT(bit 14) [Nested task
flag]这个标志控制中断链和被调用任务。若当前任务与前一个执行任务相关则置1,反之则清零。
RF(bit 16) [Resume flag]控制处理器对调试异常的响应。
VM(bit 17) [Virtual-8086 mode
flag]置1以允许虚拟8086模式,清除则返回保护模式。
AC(bit 18) [Alignment check
flag]该标志以及在CR0寄存器中的AM位置1时将允许内存引用的对齐检查,以上两个标志中至少有一个被清零则禁用对齐检查。
VIF(bit 19) [Virtual interrupt flag]该标志是IF标志的虚拟镜像(Virtual
image),与VIP标志结合起来使用。使用这个标志以及VIP标志,并设置CR4控制寄存器中的VME标志就可以允许虚拟模式扩展(virtual
mode extensions)
VIP(bit 20) [Virtual interrupt pending
flag]该位置1以指示一个中断正在被挂起,当没有中断挂起时该位清零。与VIF标志结合使用。
ID(bit 21) [Identification
flag]程序能够设置或清除这个标志指示了处理器对CPUID指令的支持。
段寄存器
段寄存器是根据内存分段的管理模式而设置的。内存单元的物理地址由段寄存器的值和一个偏移量组合而成的,这样可用两个较少位数的值组合成一个可访问较大物理空间的内存地址,x86的段寄存器有6个----CS/DS/ES/SS/FS/GS,均为16位。
CS:CS段寄存器包含代码段的段选择符,代码段保存正在执行的指令。处理器从代码段读取指令时,使用有CS寄存器中的段选择符与EIP寄存器联合构成的逻辑地址。EIP保存要执行的下一条指令在代码段中的偏移量。CS寄存器不能有应用程序显式地的加载。相反,可以通过某些指令或处理器内部操作隐式地加载。这些指令/内部操作,例如过程调用,中断处理,或者任务切换,用于改变程序的执行流,从而导致更新CS寄存器。
DS/ES/FS/GS:这四个寄存器指向四个数据段。多个数据段的存在允许高效地且安全地访问不同的数据结构类型。例如,可以创建如下的四个数据段:
第一个数据段保存当前程序模块的数据结构,
第二个数据段保存更高级别程序模块导出的数据,
第三个数据段保存动态创建的数据结构,
最后一个数据段保存另一个程序共享出来的数据。
要想访问更多的数据段,应用程序必须按需将数据段对应的段选择符加载到DS/ES/FS/GS寄存器中的其中一个当中。
SS:SS寄存器包含栈段的段选择符,这里栈段用于存储程序/任务/当前正在执行的处理器程序的栈帧。所有的栈操作都使用SS栈段寄存器来定位栈段。与CS代码段寄存器不同,SS寄存器可以显式地加载,这样就允许应用程序建立多个栈段,并在这些段间切换。
控制寄存器
控制寄存器概述:
这几个控制寄存器中保存全局性和任务无关的机器状态。控制寄存器(CR0~CR3)用于控制和确定处理器的操作模式以及当前执行任务的特性。CR0中含有控制处理器操作模式和状态的系统控制标志;CR1保留不用;CR2含有导致页错误的线性地址;CR3中含有页目录表物理内存基地址,因此该寄存器也被称为页目录基地址寄存器PDBR(Page-Directory
Base address Register)。
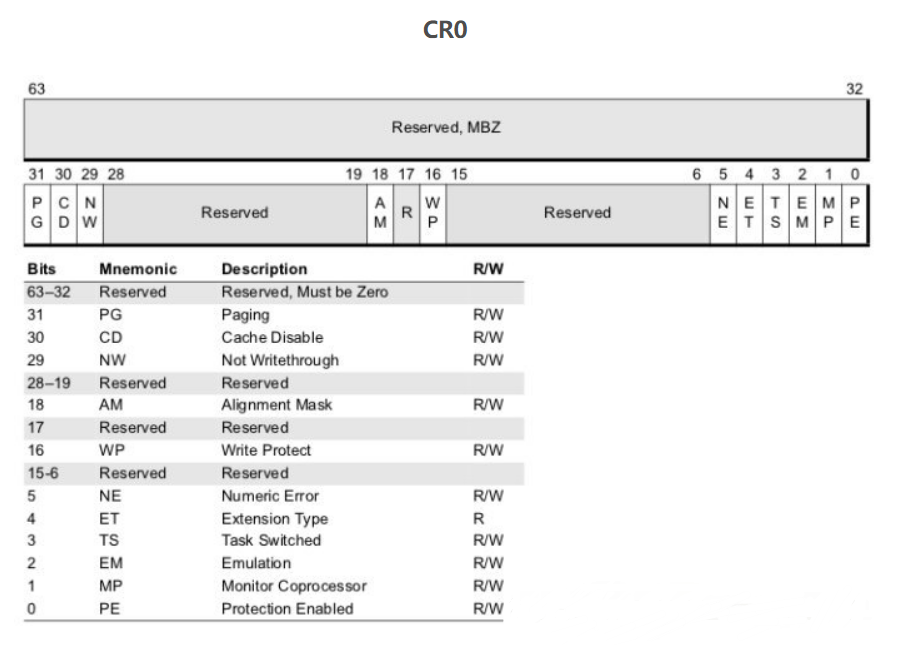
CR0中包含了6个预定义标志:
0位是保护允许位PE(Protedted
Enable),用于启动保护模式,如果PE位置1,则保护模式启动,如果PE=0,则在实模式下运行。
1位是监控协处理位MP(Moniter
coprocessor),它与第4位一起决定:当TS=1时操作码WAIT是否产生一个"协处理器不能使用"的出错信号。
3位是任务转换位(Task
Switch),当一个任务转换完成之后,自动将它置1。随着TS=1,就不能使用协处理器。
2位是模拟协处理器位 EM (Emulate
coprocessor),如果EM=1,则不能使用协处理器,如果EM=0,则允许使用协处理器。
4位是微处理器的扩展类型位ET(Processor Extension
Type),其内保存着处理器扩展类型的信息,如果ET=0,则标识系统使用的是287协处理器,如果
ET=1,则表示系统使用的是387浮点协处理器。
31位是分页允许位(Paging
Enable),它表示芯片上的分页部件是否允许工作。
CR1是未定义的控制寄存器,供将来的处理器使用。
CR2是页故障线性地址寄存器,保存最后一次出现页故障的全32位线性地址。

CR3是页目录基址寄存器,保存页目录表的物理地址,页目录表总是放在以4K字节为单位的存储器边界上,因此,它的地址的低12位总为0,不起作用,即使写上内容,也不会被理会。

这几个寄存器是与分页机制密切相关的,因此,在进程管理及虚拟内存管理中会涉及到这几个寄存器,读者要记住CR0、CR2及CR3这三个寄存器的内容
控制寄存器详解:
CR0中协处理器控制位
CR0中有用的4个位:扩展类型位ET、任务切换位TS、仿真位EM和数学存在位MP用于控制80x86浮点(数学)协处理器的操作。CR0的ET位(标志)用于选择与协处理器进行通信所使用的协议,即指明系统中使用的是80387还是80287协处理器。TS、MP和EM位用于确定浮点指令或WAIT指令是否应该产生一个设备未找到(Device
Not
Available,DNA)异常。这个异常可用来仅为使用浮点运算的任务保存和恢复浮点寄存器。对于没有使用浮点运算的任务,这样做可以加快它们之间的切换操作。
(1)ET:CR0的位4是扩展类型(Extension
Type)标志。当该标志为1时,表示指明系统中有80387协处理器,并使用32位协处理器协议。ET=0指明使用80287协处理器。如果仿真位EM=1,则该位将被忽略。在处理器复位操作时,ET位会被初始化指明系统中使用的协处理器类型。如果系统中有80387,则ET被设置成1,否则若有一个80287或者没有协处理器,则ET被设置成0。
(2)TS:CR0的位3是任务已切换(Task
Switched)标志。该标志用于推迟保存任务切换时的协处理器内容,直到新任务开始实际执行协处理器指令。处理器在每次任务切换时都会设置该标志,并且在执行协处理器指令时测试该标志。
如果设置了TS标志并且CR0的EM标志为0,那么在执行任何协处理器指令之前会产生一个设备不存在异常。如果设置了TS标志但没有设置CR0的MP和EM标志,那么在执行协处理器指令WAIT/FWAIT之前不会产生设备不存在异常。如果设置了EM标志,那么TS标志对协处理器指令的执行无影响,见表4-1。
下表显示了CR0中标志EM、MP和TS的不同组合对协处理器指令动作的影响
+:------+:------+:------+:----------------------------+:---------------------------------------+
| CR0中的标志 | 指令类型 |
±------±------±------±----------------------------±---------------------------------------+
| EM | MP | TS | 浮点 | WAIT/FWAIT |
±------±------±------±----------------------------±---------------------------------------+
| 0 | 0 | 0 | 执行 | 执行 |
±------±------±------±----------------------------±---------------------------------------+
| 0 | 0 | 1 | 设备不存在(DNA)异常 | 执行 |
±------±------±------±----------------------------±---------------------------------------+
| 0 | 1 | 0 | 执行 | 执行 |
±------±------±------±----------------------------±---------------------------------------+
| 0 | 1 | 1 | DNA异常 | DNA异常 |
±------±------±------±----------------------------±---------------------------------------+
| 1 | 0 | 0 | DNA异常 | 执行 |
±------±------±------±----------------------------±---------------------------------------+
| 1 | 0 | 1 | DNA异常 | 执行 |
±------±------±------±----------------------------±---------------------------------------+
| 1 | 1 | 0 | DNA异常 | 执行 |
±------±------±------±----------------------------±---------------------------------------+
| 1 | 1 | 1 | DNA异常 | DNA异常 |
±------±------±------±----------------------------±---------------------------------------+
在任务切换时,处理器并不自动保存协处理器的上下文,而是会设置TS标志。这个标志会使得处理器在执行新任务指令流的任何时候遇到一条协处理器指令时产生设备不存在异常。设备不存在异常的处理程序可使用CLTS指令清除TS标志,并且保存协处理器的上下文。如果任务从没有使用过协处理器,那么相应协处理器上下文就不用保存。
(3)EM:CR0的位2是仿真(EMulation)标志。当该位设置1时,表示处理器没有内部或外部协处理器,执行协处理器指令时会引起设备不存在异常;当清除时,表示系统有协处理器。设置这个标志可以迫使所有浮点指令使用软件来模拟。
(4)MP:CR0的位1是监控协处理器(Monitor coProcessor或Math
Present)标志。用于控制WAIT/FWAIT指令与TS标志的交互作用。如果MP=1、TS=1,那么执行WAIT指令将产生一个设备不存在异常;如果MP=0,则TS标志不会影响WAIT的执行。
CR0中保护控制位
(1)PE:CR0的位0是启用保护(Protection
Enable)标志。当设置该位时即开启了保护模式;当复位时即进入实地址模式。这个标志仅开启段级保护,而并没有启用分页机制。若要启用分页机制,那么PE和PG标志都要置位。
(2)PG:CR0的位31是分页(Paging)标志。当设置该位时即开启了分页机制;当复位时则禁止分页机制,此时所有线性地址等同于物理地址。在开启这个标志之前必须已经或者同时开启PE标志。即若要启用分页机制,那么PE和PG标志都要置位。
(3)WP:对于Intel 80486或以上的CPU,CR0的位16是写保护(Write
Proctect)标志。当设置该标志时,处理器会禁止超级用户程序(例如特权级0的程序)向用户级只读页面执行写操作;当该位复位时则反之。该标志有利于UNIX类操作系统在创建进程时实现写时复制(Copy
on Write)技术。
(4)NE:对于Intel 80486或以上的CPU,CR0的位5是协处理器错误(Numeric
Error)标志。当设置该标志时,就启用了x87协处理器错误的内部报告机制;若复位该标志,那么就使用PC形式的x87协处理器错误报告机制。当NE为复位状态并且CPU的IGNNE输入引脚有信号时,那么数学协处理器x87错误将被忽略。当NE为复位状态并且CPU的IGNNE输入引脚无信号时,那么非屏蔽的数学协处理器x87错误将导致处理器通过FERR引脚在外部产生一个中断,并且在执行下一个等待形式浮点指令或WAIT/FWAIT指令之前立刻停止指令执行。CPU的FERR引脚用于仿真外部协处理器80387的ERROR引脚,因此通常连接到中断控制器输入请求引脚上。NE标志、IGNNE引脚和FERR引脚用于利用外部逻辑来实现PC形式的外部错误报告机制。
启用保护模式PE(Protected
Enable)位(位0)和开启分页PG(Paging)位(位31)分别用于控制分段和分页机制。PE用于控制分段机制。如果PE=1,处理器就工作在开启分段机制环境下,即运行在保护模式下。如果PE=0,则处理器关闭了分段机制,并如同8086工作于实地址模式下。PG用于控制分页机制。如果PG=1,则开启了分页机制。如果PG=0,分页机制被禁止,此时线性地址被直接作为物理地址使用。
如果PE=0、PG=0,处理器工作在实地址模式下;如果PG=0、PE=1,处理器工作在没有开启分页机制的保护模式下;如果PG=1、PE=0,此时由于不在保护模式下不能启用分页机制,因此处理器会产生一个一般保护异常,即这种标志组合无效;如果PG=1、PE=1,则处理器工作在开启了分页机制的保护模式下。
当改变PE和PG位时,必须小心。只有当执行程序至少有部分代码和数据在线性地址空间和物理地址空间中具有相同地址时,我们才能改变PG位的设置。此时这部分具有相同地址的代码在分页和未分页世界之间起着桥梁的作用。无论是否开启分页机制,这部分代码都具有相同的地址。另外,在开启分页(PG=1)之前必须先刷新页高速缓冲TLB。
在修改该了PE位之后程序必须立刻使用一条跳转指令,以刷新处理器执行管道中已经获取的不同模式下的任何指令。在设置PE位之前,程序必须初始化几个系统段和控制寄存器。在系统刚上电时,处理器被复位成PE=0和PG=0(即实模式状态),以允许引导代码在启用分段和分页机制之前能够初始化这些寄存器和数据结构。
CR2和CR3
CR2和CR3用于分页机制。
CR3含有存放页目录表页面的物理地址,因此CR3也被称为PDBR。
因为页目录表页面是页对齐的,所以该寄存器只有高20位是有效的。
而低12位保留供更高级处理器使用,因此在往CR3中加载一个新值时低12位必须设置为0。
使用MOV指令加载CR3时具有让页高速缓冲无效的副作用。
为了减少地址转换所要求的总线周期数量,最近访问的页目录和页表会被存放在处理器的页高速缓冲器件中,该缓冲器件被称为转换查找缓冲区(Translation
Lookaside
Buffer,TLB)。只有当TLB中不包含要求的页表项时才会使用额外的总线周期从内存中读取页表项。
即使CR0中的PG位处于复位状态(PG=0),我们也能先加载CR3。
以允许对分页机制进行初始化。
当切换任务时,CR3的内容也会随之改变。
但是如果新任务的CR3值与原任务的一样,处理器就无需刷新页高速缓冲。这样共享页表的任务可以执行得更快。
CR2用于出现页异常时报告出错信息。
在报告页异常时,处理器会把引起异常的线性地址存放在CR2中。因此操作系统中的页异常处理程序可以通过检查CR2的内容来确定线性地址空间中哪一个页面引发了异常。
CR4
80486开始加入CPU

VME: 为1,允许虚拟8086模式扩展;为0,禁止虚拟8086模式扩展
PVI:为1,允许保护方式虚拟中断;为0,禁止保护方式虚拟中断
TSD:为1且当前特权级不为0是,执行RDTSC/RDTSCP(读时间标志计数器)指令,会产生错误;为0,RDTSC/RDTSCP可以在所有特权级上执行
DE:为1,允许调试扩充;为0,禁止调试扩充。所谓扩充就是是否支持I/O断点
PSE:为1,允许页面大小扩充,这个是大尺寸页面的开关;为0,禁止页面大小扩充
PAE:为1,允许物理地址扩充,支持2M大小的页;为0,禁止物理地址扩充
MCE:为1,允许机器检查异常;为0,禁止机器机器检查异常
PGE:为1,允许全局页访问;为0,禁止全局页访问
PCE:为1,允许用RDPMC指令访问一些关键寄存器;为0,禁止非最高权限使用RDPMC
实模式:内存访问空间1M,直接访问物理地址
保护模式:内存访问空间4G,有保护模式机制,地址是映射的,不能直接访问物理地址
虚拟8086模式:在保护模式下运行实模式程序,伪物理地址访问(保护模式机制仍然存在)
调试寄存器
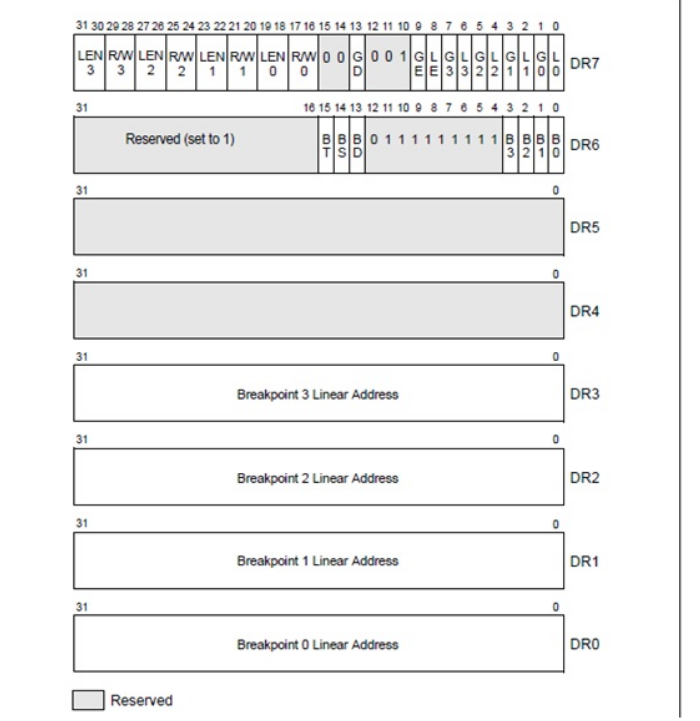
DR0-DR3:保留32位断点的线性地址。这四个寄存器是用来设置 断点地址的。断点的比对在物理地址转换前(异常产生时,还没有将线性地址转换成物理地址)。由于只有0-3四个保存地址的寄存器,所以,硬件断点,在物理上最多只能有4个。
DR4-DR5:保留、未定义。
DR7:用于控制调试过程的
- L0-L3(由第0,2,4,6位控制):对应DR0-DR3,设置断点作用范围,如果被置位,那么将只对当前任务有效。每次异常后,Lx都被清零。
2. G0-G3(由第1,3,5,7位控制):对应DR0-DR3,如果置位,那么所有的任务都有效。每次异常后不会被清零。以确保对所有任务有效。但是,不知道为什么,我在测试时:
设置Gn后,不能返回调试异常给调试器(如果你知道为什么,记得告诉我)
3. LE,GE(由第8,9位控制):这个在P6以下系列CPU上不被支持,在升级版的系列里面:如果被置位,那么cpu将会追踪精确的数据断点。LE是局部的,GE是全局的。(到底什么算精确的,我也不清楚,但是,我知道如果设置了这两个,cpu的速度会降低。我在测试中,都没有置位。)
4. GD(由第13位控制):如果置位,追踪下一条指令是否会访问调试寄存器。如果是,产生异常。在下面的DR6里面,你会知道他还和另外一个标志位有点关系。
5. R/W0-R/W3:(由第16,17,20,21,24,25,28,29位控制):这个东西的处理有两种情况。
如果CR4的DE被置位,那么,他们按照下面的规则处理问题:
00:执行断点
01:数据写入断点
10:I/0读写断点
11:读写断点,读取指令不算
如果DE置0,那么问题会这样处理:
00:执行断点
01:数据写入断点
10:未定义
11:数据读写断点,读取指令不算
6. LEN0-LEN3:(由第18.19.22.23.26.27.30位控制):指定内存操作的大小。
00:1字节(执行断点只能是1字节长)
01:2字节
10:未定义或者是8字节(和cpu的系列有关系)
11:4字节
DR6:
这个寄存器主要是在调试异常产生后,报告产生调试异常的相关信息
1. B0-B3(DR0-DR3):DRx指定的断点在满足DR7指定的条件下,产生异常。那么Bx就置位。但是,有时,即使Ln和Gn置0,也可能产生Bx被置位。
这种现象可能这样出现(提示:在p6系列处理器,REP MOVS在不断循环中产生的调试异常需要执行完了才能准确返回给调试进程):DR0的L0,G0都置0(DR0就是一个不能产生异常的断点了),然后在DR0指定的地址是一个REP指令的循环,这样,DR0就可能在这个循环之后的REP指令产生的调试异常中将B0置位
2. BD:BD需要DR7的GD置位,才有效。BD是在下一条指令要访问到某一个调试寄存器的时候,被置位的。
3. BS:单步执行模式时,被置位。单步执行是最高权限的调试异常。
4. BT:在任务切换的时候,被置位。但是必须在被切换去的任务的TSS段里面的T标记被置位的情况下才有效。在控制权被切换过去后,在执行指令前,返回调试异常。但是,需要注意,如果调试程序是一个任务,那么T标记的设置肯定就冲突了。然后,导致了死循环(BT的这些信息都是按照官方资料翻译而来,由于没有实际的操作,肯定会有理解上的出入。如果要深入的话,建议看官方资料)
有些调试异常会将B0-B3清零。但是其他的DR6的位是不能被产生异常的进程清零的。每次调试异常返回后,调试进程都会先将DR6清零,再按照情况设置。以免产生不必要的错误。
在window中,可以通过GetThreadContext函数来获取,通过SetThreadContext函数来设置
使用参数ContextFlags:CONTEXT_DEBUG_REGISTERS来控制两个函数进行处理
系统地址寄存器
全局描述符表GDT、局部描述符表LDT和中断描述符表IDT等都是保护方式下非常重要的特殊段,它们包含有为段机制所用的重要表格。为了方便快速地定位这些段,处理器采用一些特殊的寄存器保存这些段的基地址和段界限。我们把这些特殊的寄存器称为系统地址寄存器。
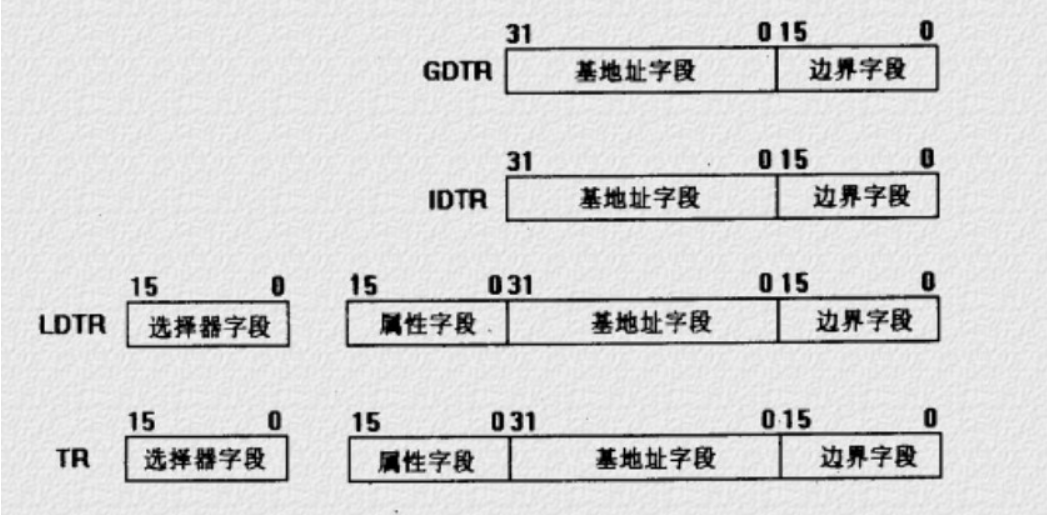
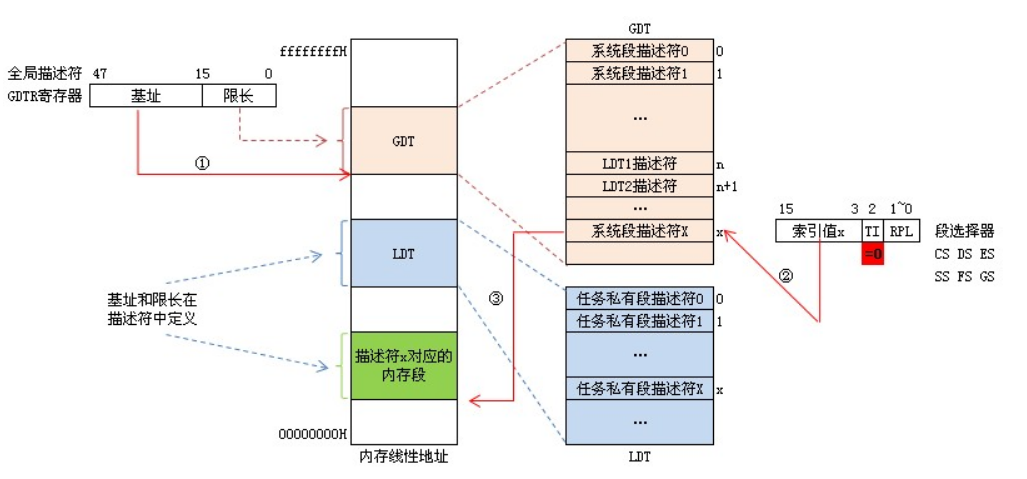
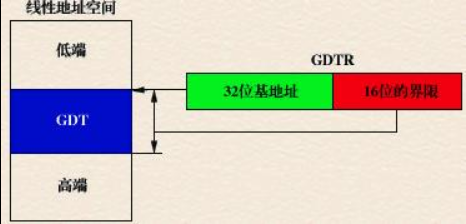
1.全局描述符表寄存器GDTR:GDTR长48位,其中高32位为基地址,低16位为界限。由于GDT
不能有GDT本身之内的描述符进行描述定义,所以处理器采用GDTR为GDT这一特殊的系统段提供一个伪描述符。GDTR给定了GDT。GDTR中的段界限以字节为单位。由于段选择子中只有13位作为描述符索引,而每个描述符长8个字节,所以用16位的界限足够。通常,对于含有N个描述符的描述符表的段界限设为8*N-1。
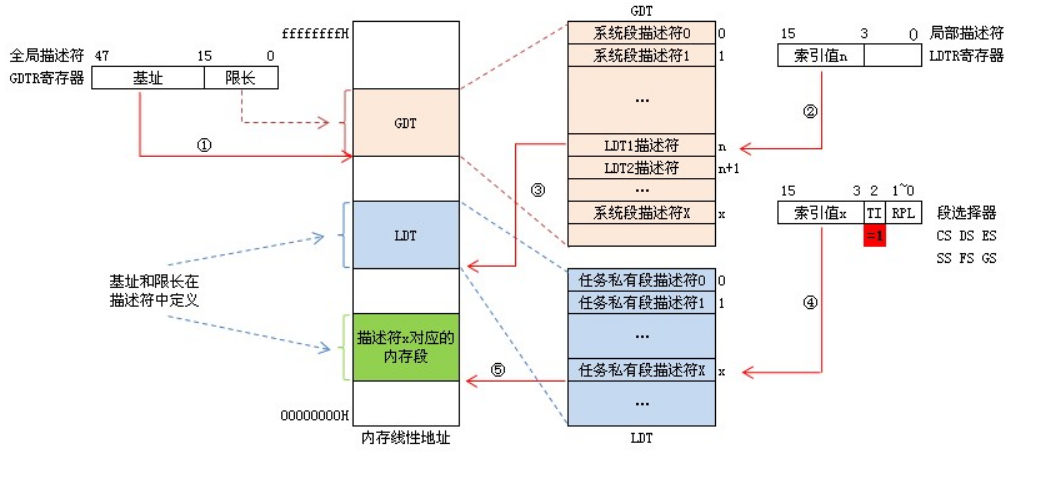
2.局部描述符表寄存器LDTR:局部描述符表寄存器LDTR规定当前任务使用的局部描述符表LDT。LDTR类似于段寄存器,由程序员可见的16位的寄存器和程序员不可见的高速缓冲寄存器组成。实际上,每个任务的局部描述符表LDT作为系统的一个特殊段,由一个描述符描述。而用于描述符LDT的描述符存放在GDT中。在初始化或任务切换过程中,把描述符对应任务LDT的描述符的选择子装入LDTR,处理器根据装入LDTR可见部分的选择子,从GDT中取出对应的描述符,并把LDT的基地址、界限和属性等信息保存到LDTR的不可见的高速缓冲寄存器中。随后对LDT的访问,就可根据保存在高速缓冲寄存器中的有关信息进行合法性检查。LDTR寄存器包含当前任务的LDT的选择子。所以,装入到LDTR的选择子必须确定一个位于GDT中的类型为LDT的系统段描述符,也即选择子中的TI位必须是0,而且描述符中的类型字段所表示的类型必须为LDT。可以用一个空选择子装入LDTR,这表示当前任务没有LDT。在这种情况下,所有装入到段寄存器的选择子都必须指示GDT中的描述符,也即当前任务涉及的段均由GDT中的描述符来描述。如果再把一个TI位为1的选择子装入到段寄存器,将引起异常。
3.中断描述符表寄存器IDTR:中断描述符表寄存器IDTR指向中断描述符表IDT。IDTR长48
位,其中32位的基地址规定IDT的基地址,16位的界限规定IDT的段界限。由于80386只支持256个中断异常,所以IDT表最大长度是2K,以字节位单位的段界限为7FFH。IDTR
指示IDT的方式与GDTR指示GDT的方式相同。
- 任务状态段寄存器TR:任务状态段寄存器TR包含指示描述当前任务的任务状态段的描述符选择子,从而规定了当前任务的状态段。任务状态段的格式在后面的文章中介绍。TR也有程序员可见和不可见两部分。当把任务状态段的选择子装入到TR可见部分时,处理器自动把选择子所索引的描述符中的段基地址等信息保存到不可见的高速缓冲寄存器中。在此之后,对当前任务状态段的访问可快速方便地进行。装入到TR的选择子不能为空,必须索引位于GDT中的描述符,且描述符的类型必须是TSS。
其他寄存器
EIP
主要用于存放当前代码段即将被执行的下一条指令的偏移,但其本质上并不能直接被指令直接访问。这个寄存器指令由控制转移指令、中断及异常所控制。读操作通过执行call指令并取得栈中所存放的地址来实现,而写操作则通过修改程序栈中的返回指令指针并执行RET/IRET指令来完成,因此尽管这个寄存器相当重要,但其实并不是操作系统在实现过程中所需关注的焦点。
TSC
时间戳寄存器 Time Stamp
Counter每个时钟周期时其值加1,重启时清零。通过RDTSC指令读取TSC寄存器,只有当CR4寄存器的TSD位为0时,才可以在任何优先级下执行该指令,否则只能在特权级下执行该指令。
浮点寄存器
由于在80486微处理器内部设有浮点运算器,因此在其内部有相应的寄存器,其中包括8个80位通用数据寄存器、1个48位指令指针寄存器、1个48位数据指针寄存器、1个16位控制字寄存器、1个16位状态字寄存器和1个16位标记字寄存器。
寻址方式
立即寻址
指令所需要的操作数直接在指令码中,也就是立即数
一般用imm8/16/32/64 表示8位/16位/32位/64位立即数
直接寻址
操作数是一个地址值
一般用[地址值]来表示
例子:MOV AX,[2000H]
寄存器寻址
操作数是一个寄存器
比如:MOV AX,BX
这里的AX和BX都是寄存器寻址
寄存器间接寻址
寄存器里面的值是地址值
比如:[BP/BX][SI/DI]
一般BX/SI/DI都是DS段的偏移地址,BP是SS段的偏移地址
寄存器相对寻址
操作数地址是间址寄存器+偏移量(可为负数)
比如:MOV AX,[SI+10H] 或者 MOV AX,10H[SI]
基址变址寻址
操作数地址是基址寄存器+变址寄存器
比如:MOV AX,[BX+SI]
常用传送指令和取有效地址指令
MOV指令
格式:MOV 目标 ,源
目标
是指要存储的位置,可以是[内存地址]{.underline}或者[寄存器]{.underline}
源
是指读取的源头位置,可以是[立即数]{.underline}、[内存地址]{.underline}或者[寄存器]{.underline}
这里的寄存器包括通用寄存器、段寄存器、控制寄存器、调试寄存器等
对标志位的影响:无
效果:将源中的数据或者源指向的数据,传送到目标之中或者目标指向的数据之中
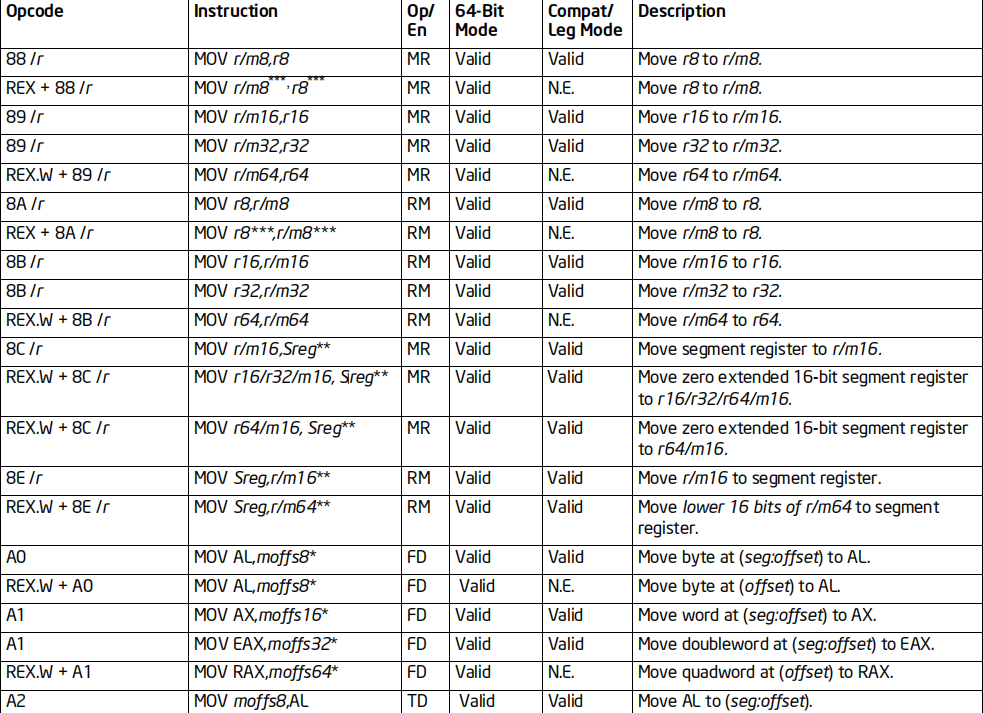
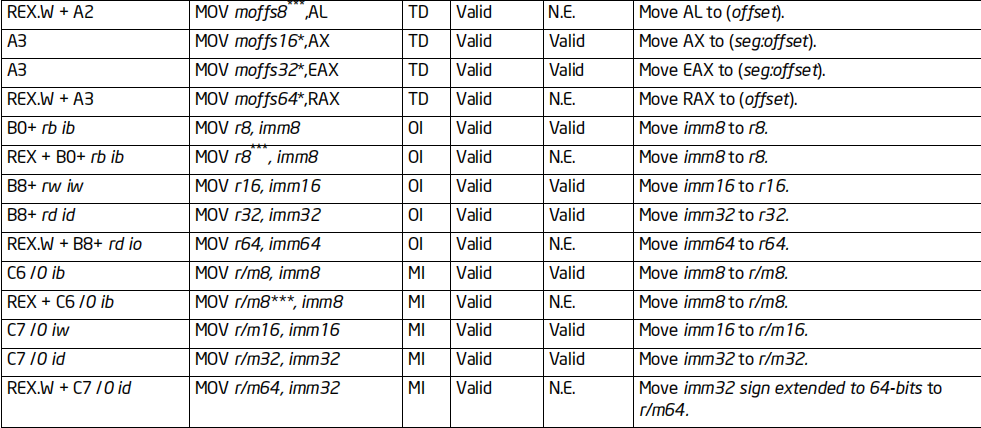
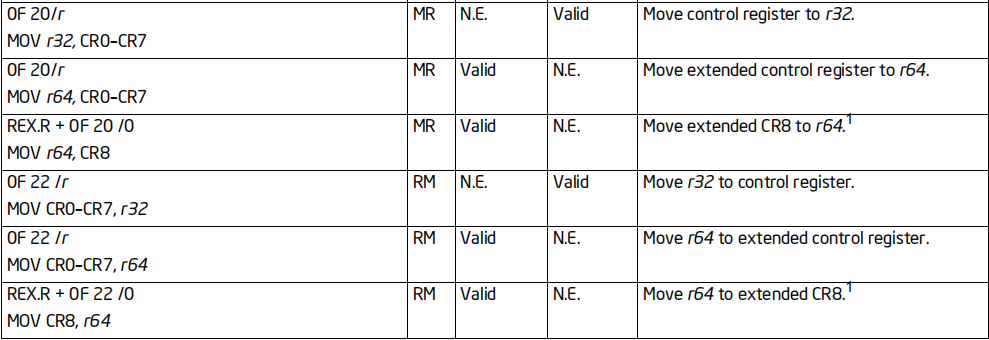
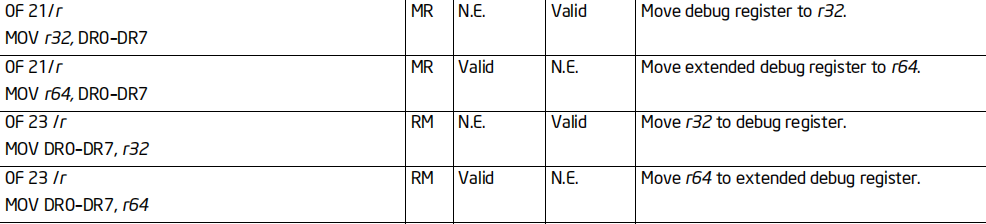
所有的MOV指令都支持64位扩展,但是不是所有的指令都能在传统CPU上运行
下面这几张图,列举了MOV指令的实际情况(数据来源于Intel官方指令集文档)
LEA指令
LEA = Load Effective Address
格式:LEA 寄存器,内存目标
对标志位的影响:无
效果:加载有效地址到寄存器
64位支持:支持
内存目标可以是如下形式:
Imm[DI/SI]
标号,例如:TABLE
[通用寄存器][SI/DI] 基址加变址寻址

备注:
1 如果操作数不是一个内存地址,或者地址被LOCK了,那么行为不可知
2
寄存器可以是16位、32位或者64位,如果地址值大于寄存器的有效位,低位会被加载
如果地址值低于寄存器的有效位,高位会被用零填满
加减指令集
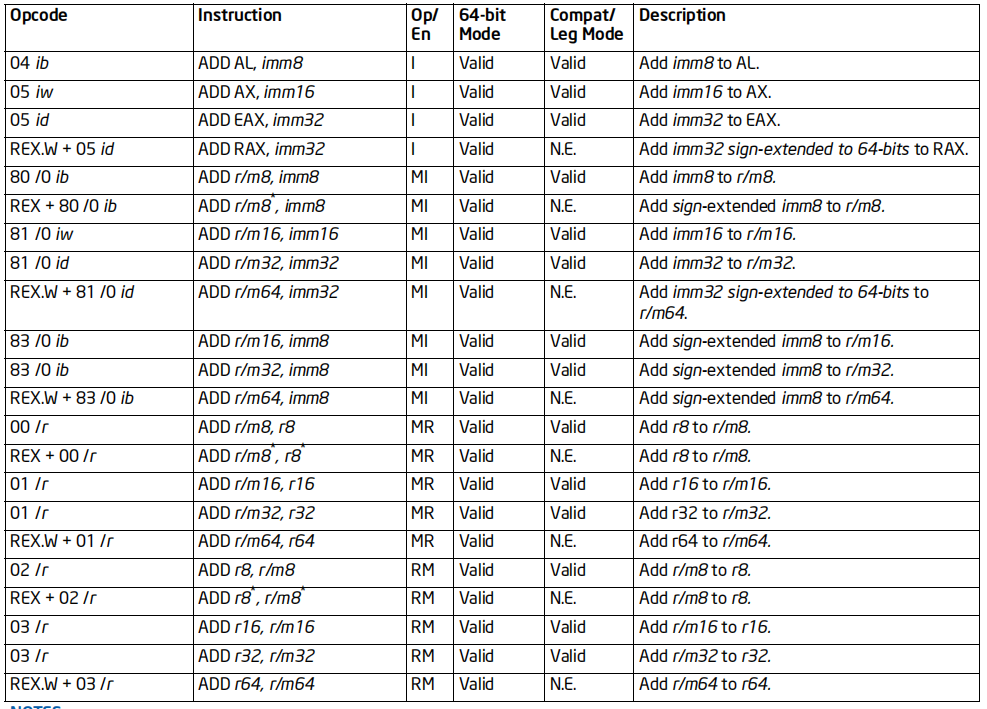
ADD指令
格式:ADD 被加数,加数
标志位的影响:OF, SF, ZF, AF, CF, PF
效果:将被加数和加数相加,结果保存到被加数
64位支持:支持
SUB指令
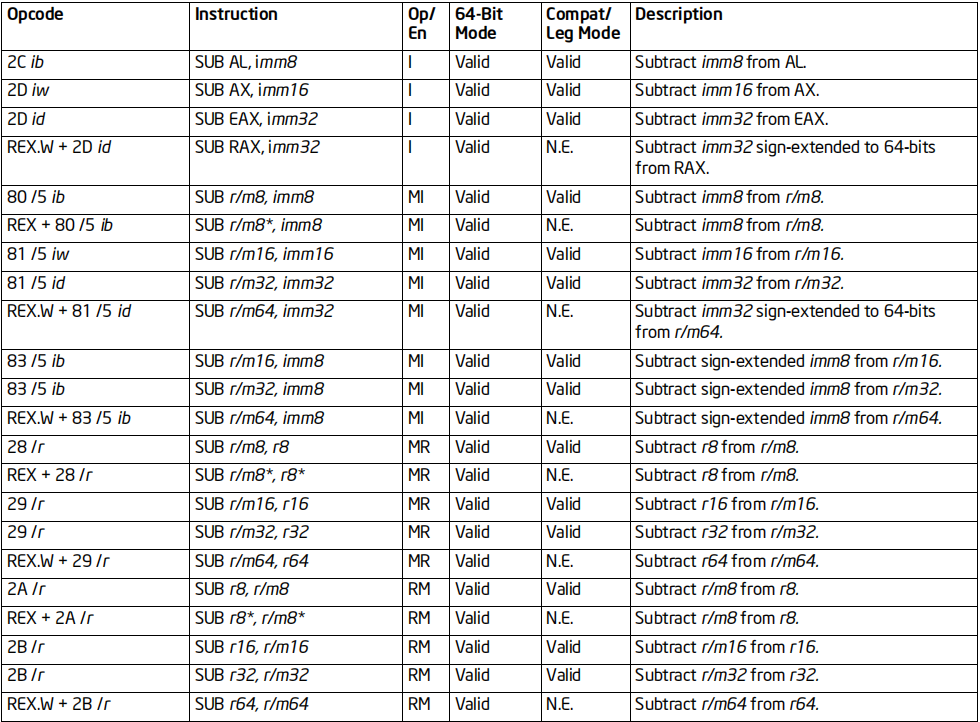
格式:SUB 被减数,减数
标志位的影响:OF, SF, ZF, AF, CF, PF
效果:将被减数和减数相减,结果保存到被减数
64位支持:支持
INC指令
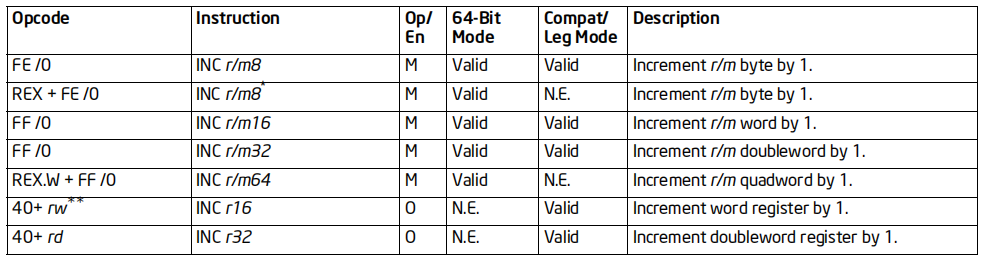
格式:INC 操作数
标志位的影响:OF, SF, ZF, AF, PF
效果:操作数加1存入操作数
64位支持:部分情况不支持(64位下不支持AH,BH,CH,DH)
备注:不影响CF
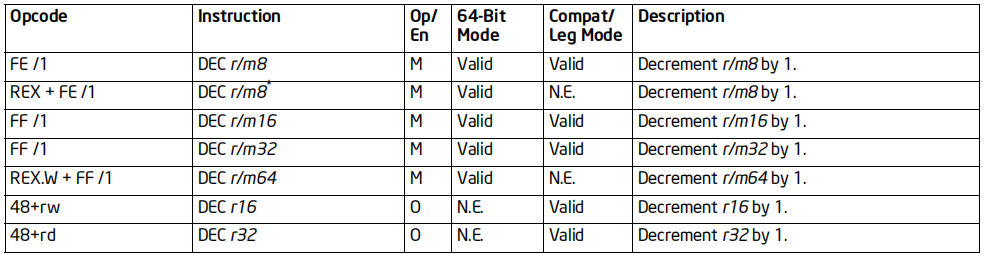
DEC指令
格式:DEC 操作数
标志位的影响:OF, SF, ZF, AF, PF
效果:操作数减1存入操作数
64位支持:部分情况不支持(64位下不支持AH,BH,CH,DH)
NEG指令
格式:NEG 操作数
标志位的影响:[CF]{.underline}, [OF]{.underline}, SF, ZF,
[AF]{.underline}, PF
效果:操作数=-操作数
64位支持:64位下不支持AH,BH,CH,DH

备注:
当操作数位0时,CF被置0;当操作数不为0时,CF被置1
当低4位非0的情况下,AF就会为1;否则AF为0
当发生OF的时候,操作数,不会发生改变
标志寄存器及其使用
PUSHF/PUSHFD/PUSHFQ指令
格式:PUSHF/PUSHFD/PUSHFQ
标志位的影响:无
效果:将标志位入栈(读入到内存)
64位支持:不同的模式使用不同的指令

备注:只有标志位是可信的,其他的位会受到控制寄存器的影响
入栈的时候,先保存的高8位,然后保存的低8位,一共保存16位
POPF/POPFD/POPFQ指令
格式:POPF/POPFD/POPFQ
标志位的影响:全部标志位
效果:从栈中读取标志位数据,并恢复到标志位寄存器
64位支持:对于64位环境,会把高位按0扩展后写入

备注:POPF和POPFD对标志寄存器的影响效果见下表
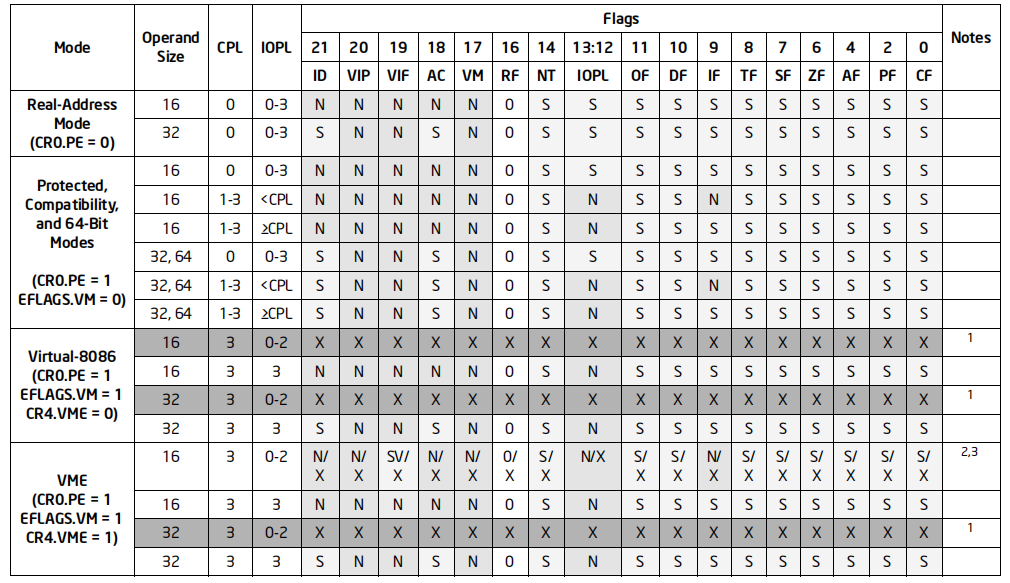
不同模式下有不同的效果
S表示从栈更新
SV表示从栈更新IF标志
N表示值不会变化
X表示EFLAGS不会更新对应位
0表示该位被置0
比较和跳转指令集
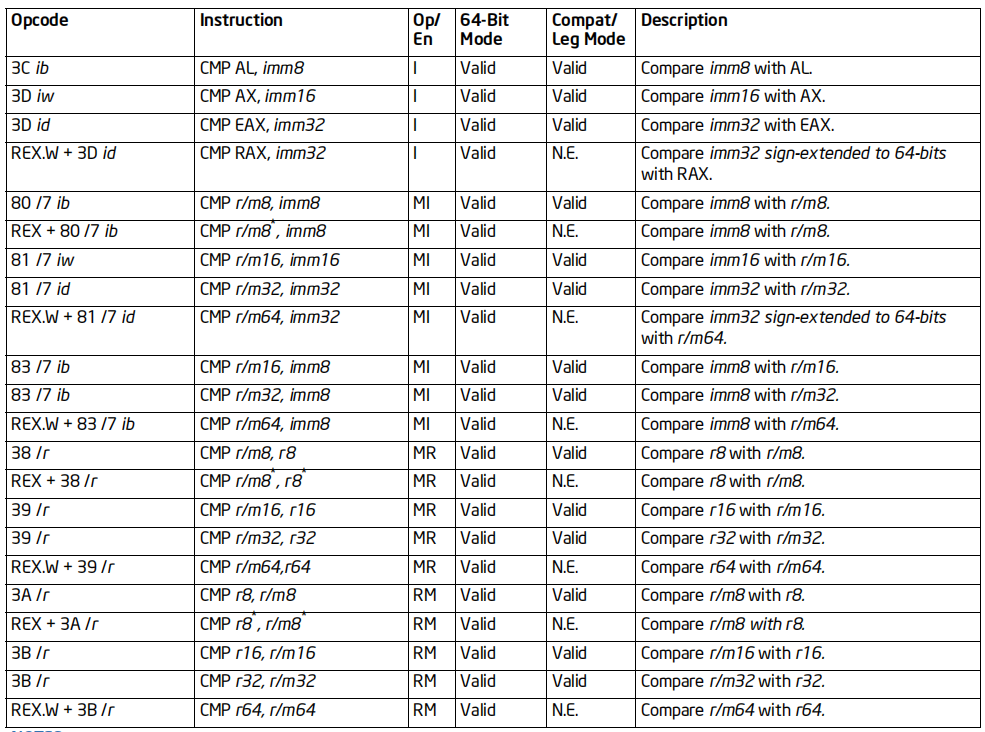
CMP指令
格式:CMP 操作数1, 操作数2
标志位的影响:OF, SF, ZF, AF, CF, PF
效果:操作数1-符号扩展(操作数2),并影响标志位
64位支持:64位下不支持AH,BH,CH,DH
TEST指令
格式:TEST 操作数1, 操作数2
标志位的影响:OF、CF变为0;SF,ZF,PF依赖结果;AF结果未定义
效果:计算 操作数1 AND 操作数2,结果不保留
64位支持:64位下不支持AH,BH,CH,DH
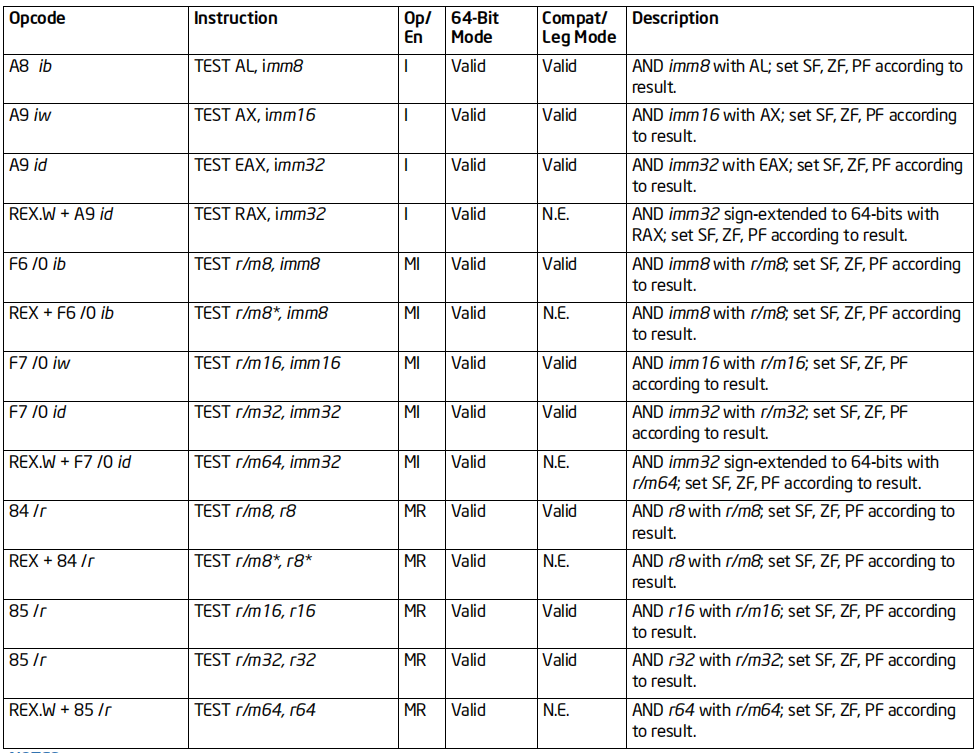
备注:
二进制下:
任何数与上自己,结果等于自己
任何数与上1,结果等于自己
JMP系列指令
格式:Jcc 地址
标志位的影响:无
效果:跳转到指定地址,然后执行代码
64位支持:部分情况不支持
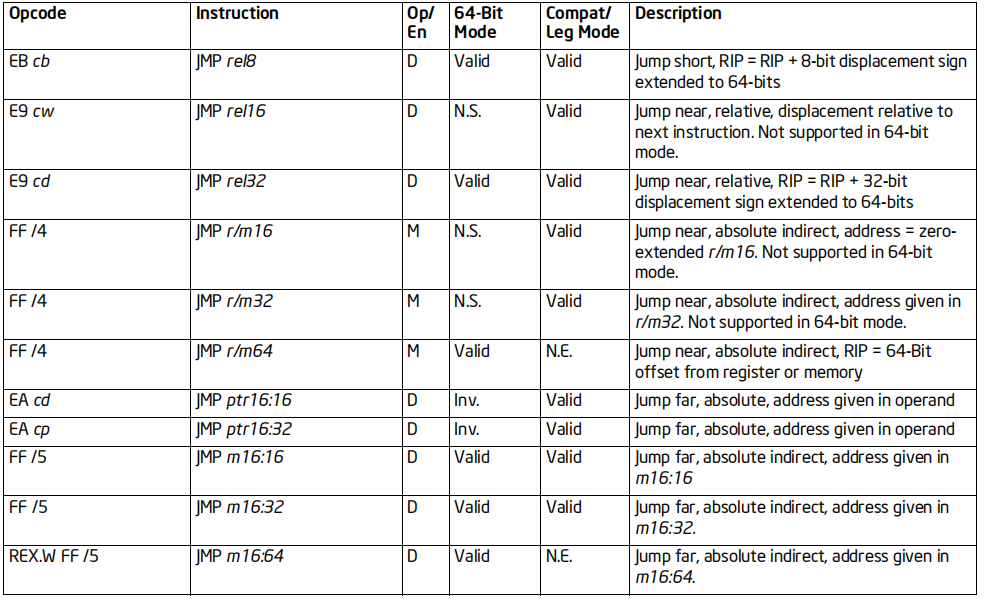
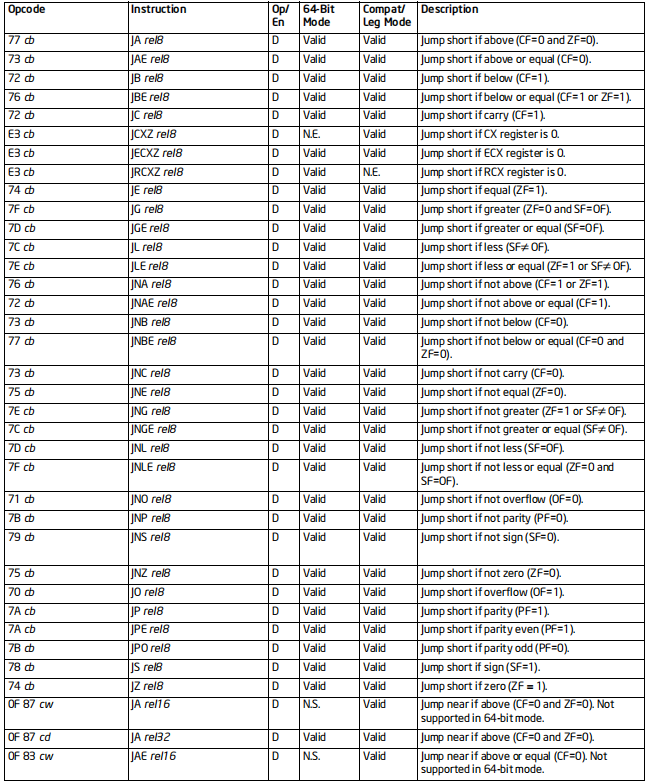
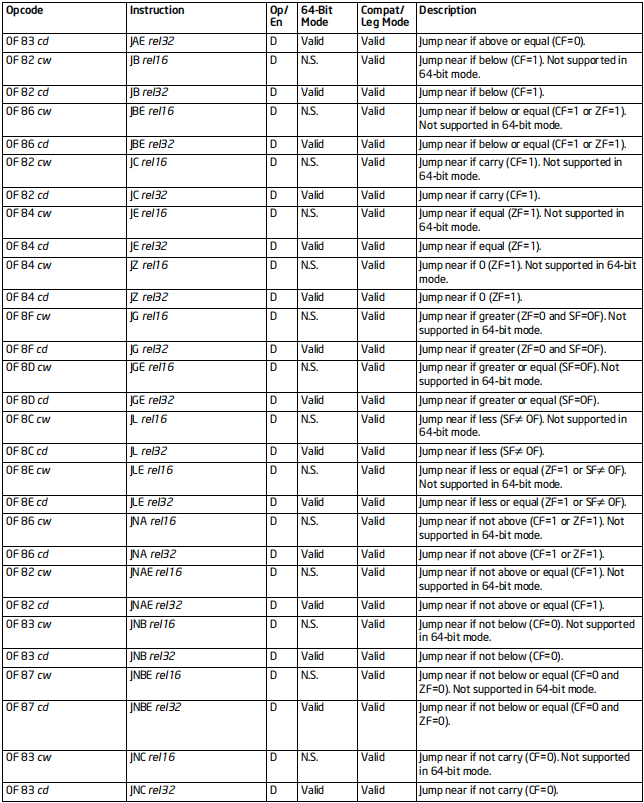
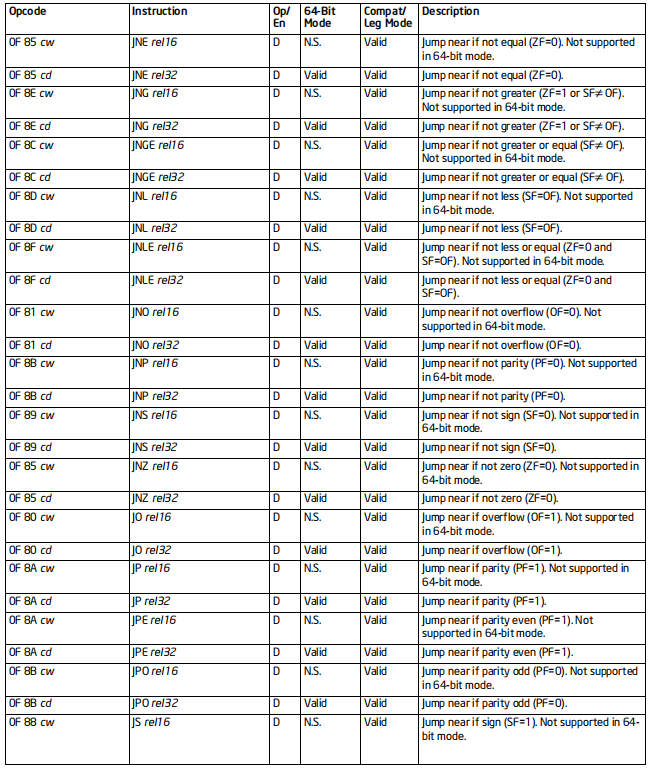

当cc为条件时,地址只能是立即数(rel8 rel16 rel32)
[rel地址是一个相对地址,可能是正数,也可能是负数或者零]{.underline}
备注:
cc的值和其含义
MP 无条件
A=above 高于 ZF=0或者CF=0
B=blow 低于 CF=1
E=equal 等于 ZF=1
N=not 不
C=carry 进位 CF=1
G=great 大于 SF=OF且ZF=0
L=less 小于 SF!=OF
O=overflow 溢出 OF=1
P=parity even奇偶校验为偶 PF=1
S=sign 为负 SF=1
Z=zero 为0 ZF=1
A/NBE ZF=0或者CF=0 等价于i>j
AE/NB/NC CF=0 等价于i>=j
B/C/NAE CF=1 等价于i<j
BE/NA ZF=1或者CF=1 等价于i<=j
[CXZ/ECXZ/RCXZ CX/ECX/RCX=0 等价于CX/ECX/RCX为0
只能是8位立即数]{.underline}
E/Z ZF=1 等价于ij或者i0
NE/NZ ZF=0 等价于i!=0或者i!=j
G/NLE SF=OF且ZF=0 等价于si>sj s表示带符号比较
GE/NL SF=OF 等价于si>=sj
L/NGE SF!=OF 等价于si<sj
LE/NG SF!=OF或ZF=1 等价于si<=sj
NO OF=0 没有溢出
O OF=1 溢出了
NP/PO PF=0 低八位包含奇数个1
P/PE PF=1 低八位包含偶数个1
NS SF=0 等价于i>=0
S SF=1 等价于i<0
堆栈操作指令集
PUSH指令
格式:PUSH 操作数
标志位的影响:无
效果:操作数入栈,ESP减去对应的长度
64位支持:支持
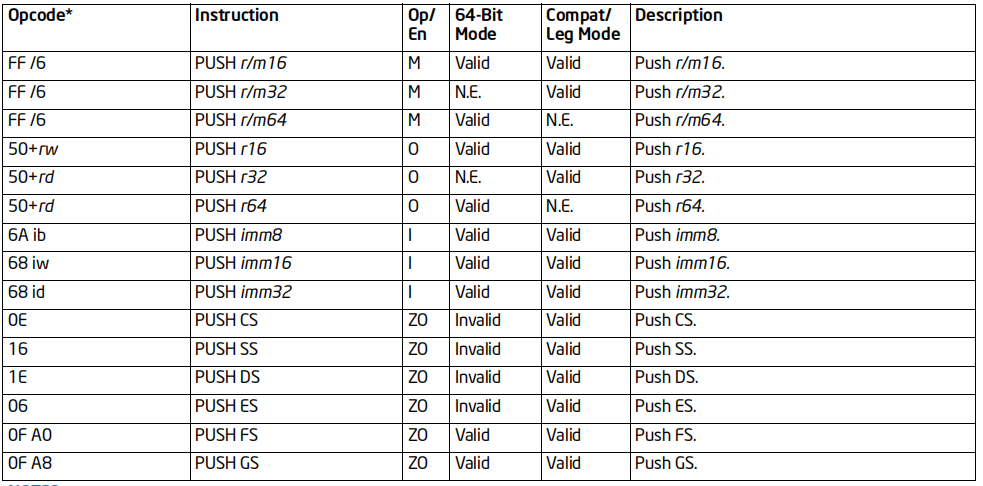
备注:使用PUSH,千万要保持栈的平衡:要么对应的使用POP,要么恢复ESP
入栈的顺序,是从高到低,按字节入栈
POP指令
格式:POP 操作数
标志位的影响:无
效果:操作数出栈
64位支持:支持
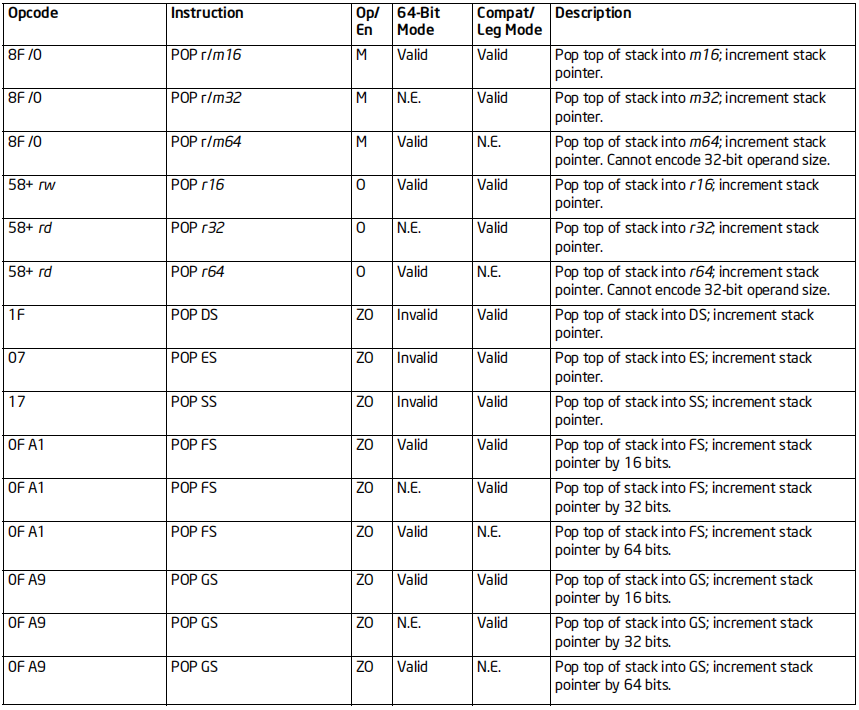
备注:POP可以修改段寄存器
会影响ESP寄存器
PUSHA/PUSHAD指令
格式:PUSHA/PUSHAD
标志位的影响:无
效果:
PUSHA将AX、CX、DX、BX、SP、BP、SI、DI按顺序入栈
PUSHAD将EAX、ECX、EDX、EBX、ESP、EBP、ESI、EDI按顺序入栈
64位支持:不支持

POPA/POPAD指令
格式:POPA/POPAD
标志位的影响:无
效果:
POPA将DI、SI、BP、SP、BX、DX、CX、AX按顺序出栈
POPAD将EDI、ESI、EBP、ESP、EBX、EDX、ECX、EAX按顺序出栈
64位支持:不支持

函数调用指令
CALL指令
格式:CALL 地址
标志位的影响:
如果发生了任务切换,则所有标志位可能都会受到影响
如果没有任务切换,则所有标志位都不会受到影响
效果:下一条指令地址入栈,跳到目标进行指令执行
64位支持:支持
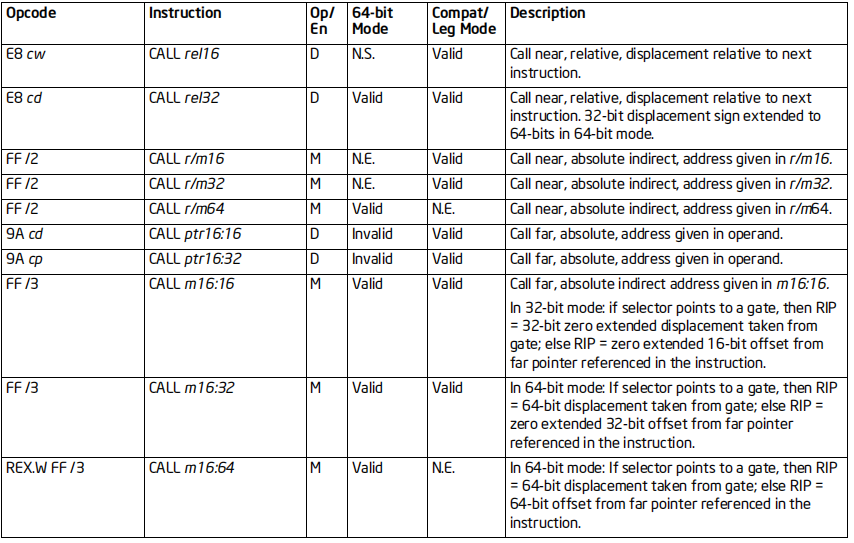
RET指令
格式:RET [imm16]
标志位的影响:无
效果:
从子程序返回(从栈中恢复地址)
如果带参数,则从栈中弹出imm16个字节
64位支持:支持
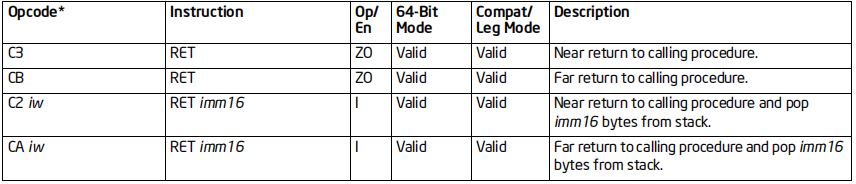
常用的乘除法指令
MUL指令
格式:MUL 乘数
标志位的影响:如果结果高半截为0,OF、CF置零,否则置1;SF、ZF、AF、PF未定义
效果:AL/AX/EAX/RAX里面的数乘以乘数,结果存回到AX/DX:AX/EDX:EAX/RDX:RAX
64位支持:部分情况不支持(64位下不支持AH,BH,CH,DH)
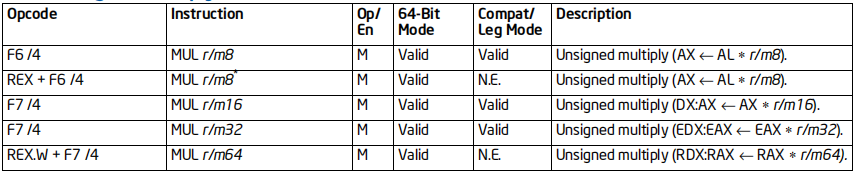
IMUL指令
格式:
1 IMUL 乘数
-
IMUL 被乘数, 乘数
-
IMUL 结果, 被乘数, 乘数**(立即数)**
标志位的影响:
如果结果的高半部分不是低半部分的符号扩展,则CF和OF置1;SF、ZF、AF、PF未定义
效果:
对于1,参考MUL
对于2,被乘数×乘数→被乘数
对于3,结果=被乘数×乘数
64位支持:部分情况不支持(64位下不支持AH,BH,CH,DH)
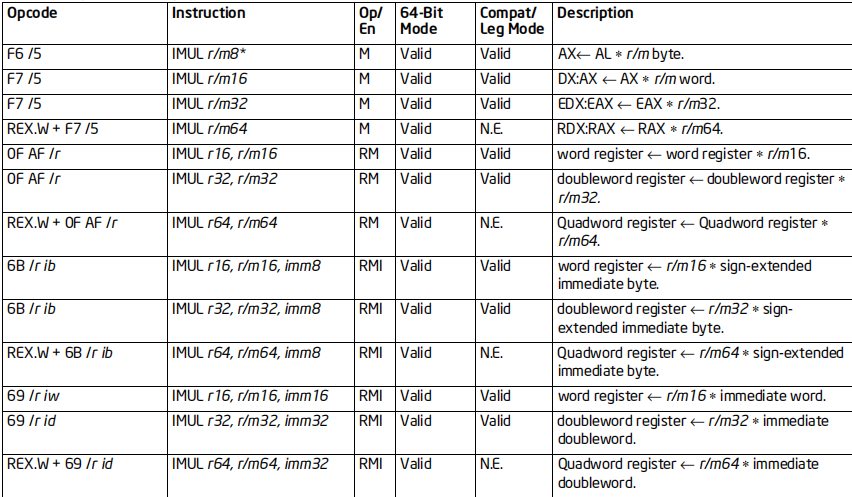
DIV指令
格式:DIV 除数
标志位的影响:所有标志位影响未定义
效果:
用AX除8位除数,结果存放AL,余数存放AH
用DX:AX除16位除数,结果存放AX,余数存放DX
用EDX:EAX除32位除数,结果存放EAX,余数存放EDX
用RDX:RAX除64位除数,结果存放RAX,余数存放RDX
64位支持:部分情况不支持(64位下不支持AH,BH,CH,DH)
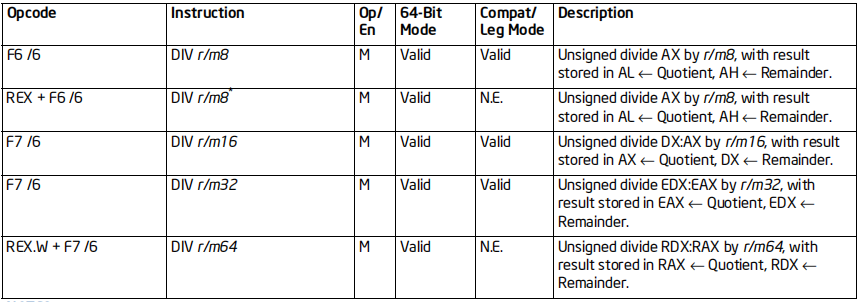
备注:结果一定要能够存入结果寄存器中,否则可能导致整数溢出异常
IDIV指令
格式:IDIV 除数
标志位的影响:所有标志位影响未定义
效果:
用AX除8位除数,结果存放AL,余数存放AH
用DX:AX除16位除数,结果存放AX,余数存放DX
用EDX:EAX除32位除数,结果存放EAX,余数存放EDX
用RDX:RAX除64位除数,结果存放RAX,余数存放RDX
64位支持:部分情况不支持(64位下不支持AH,BH,CH,DH)
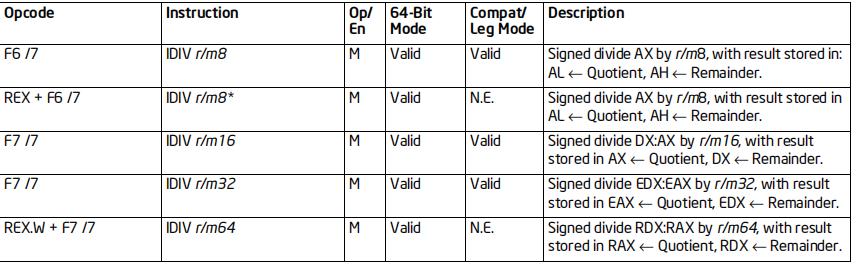
备注:
被除数和除数,是有一个范围的
结果(不是余数)应该要能够存入结果寄存器
如果被除数是64位,那么除数就不应该小于32位,否则就会产生异常
这就是整数除法的局限性
整数拓展指令
CBW/CWDE/CDQE指令
格式:CBW/CWDE/CDQE
标志位的影响:无
效果:
AL符号扩展为AX
AX符号扩展为EAX
EAX符号扩展为RAX
64位支持:

CWD/CDQ/CQO指令
格式:CWD/CDQ/CQO
标志位的影响:无
效果:
AX符号扩展为DX:AX
EAX符号扩展为EDX:EAX
RAX符号扩展为RDX:RAX
64位支持:

备注:
如果AX/EAX/RAX为整数(符号位/最高位为0),那么执行之后DX/EDX/RDX结果为0;
否则,结果为1
拓展传送指令
MOVSX/MOVSXD指令
格式:MOVSX/MOVSXD 目标, 源
标志位的影响:无
效果:符号扩展传送
64位支持:支持
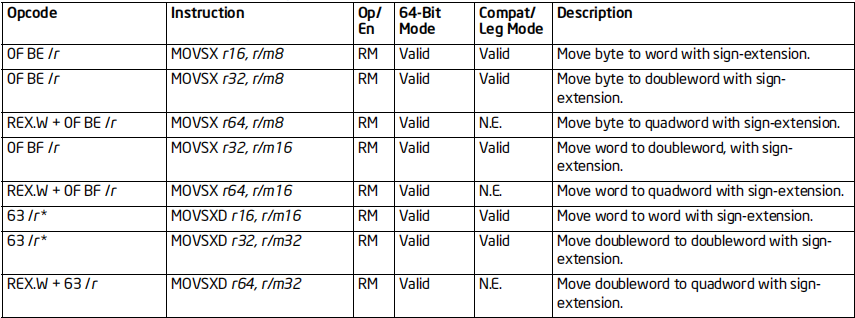
MOVZX指令
格式:MOVZX 目标寄存器, 源
标志位的影响:无
效果:0扩展传送
64位支持:部分情况不支持(64位下不支持AH,BH,CH,DH)
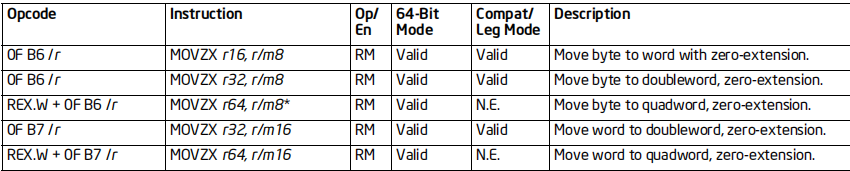
备注:
error A2218: AH, BH, CH, or DH may not be used with R8-R15, BPL, DIL,
SIL, or SPL

MOVSS指令
格式:MOVSS 目标浮点寄存器, 源
标志位的影响:无
效果:单精度数赋值到浮点寄存器
64位支持:支持


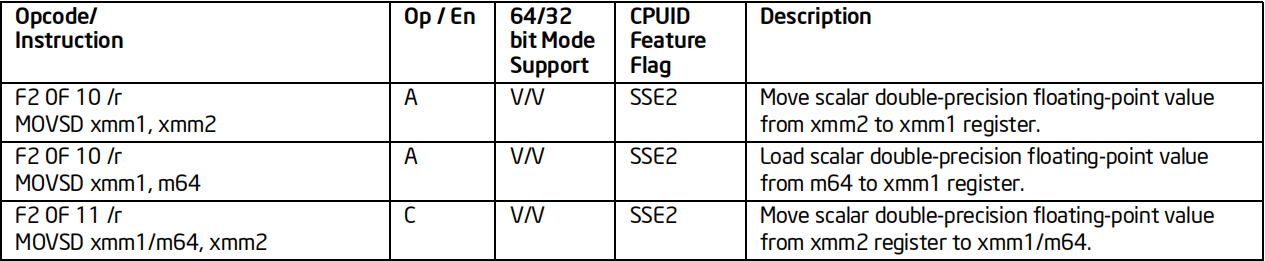
MOVSD指令
格式:MOVSD 目标浮点寄存器, 源
标志位的影响:无
效果:双精度赋值到寄存器
64位支持:支持
MOVS/MOVSB/MOVSW/MOVSD/MOVSQ指令
格式:
MOVS 目标内存, 源内存
MOVSB/MOVSW/MOVSD/MOVSQ
标志位的影响:无
效果:内存传送;如果没有指明目标和源,则默认是DS:(R/E)SI到ES:(R/E)DI
64位支持:支持
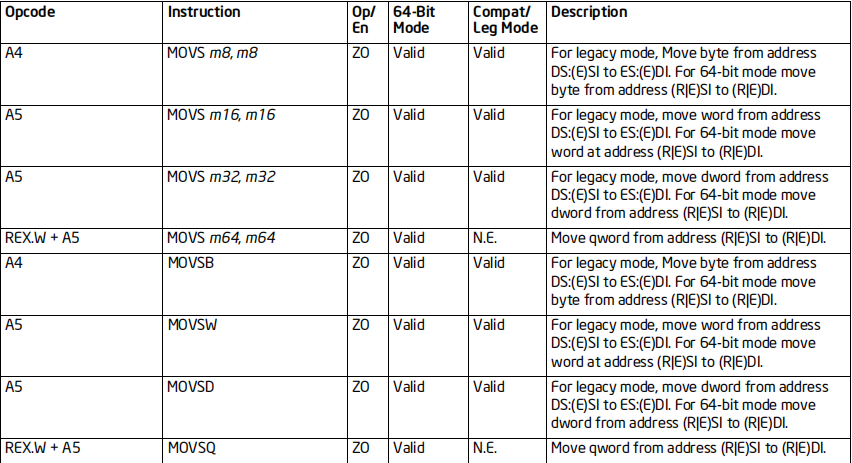
备注:
在32位CPU中MOVSQ和MOVS m64,m64不支持
这两条指令,在64位CPU环境下,才可以支持和运行
逻辑运算指令
AND指令
格式:AND 操作数1, 操作数2
标志位的影响:OF、CF置零;SF、ZF、PF依赖结果;AF行为未定义
效果:将操作数1和操作数2进行按位与运算,结果保存到操作数1
64位支持:64位下,不支持AH、BH、CH、DH寄存器
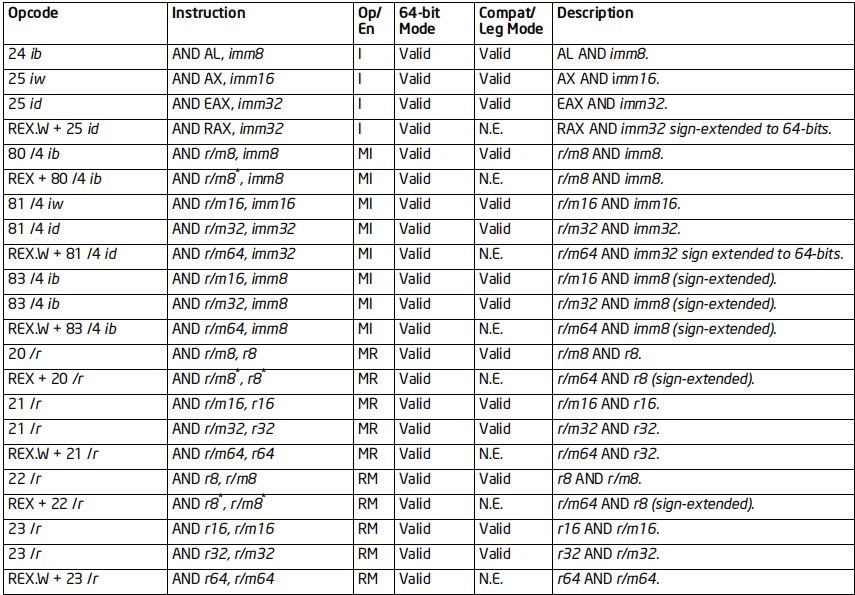
NOT指令
格式:NOT 操作数
标志位的影响:无
效果:进行位取反操作,每个位的1改为0,0则改为1,结果存入操作数
64位支持:部分情况不支持(64位下不支持AH,BH,CH,DH)
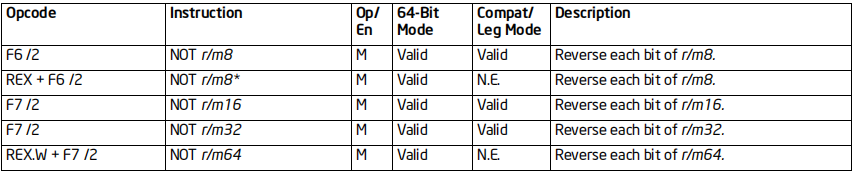
OR指令
格式:OR 目标, 源
标志位的影响:OF、CF清零;SF、ZF、PF影响;AF未定义
效果:将目标和源按位或操作,结果存入目标中
64位支持:部分情况不支持(64位下不支持AH,BH,CH,DH)
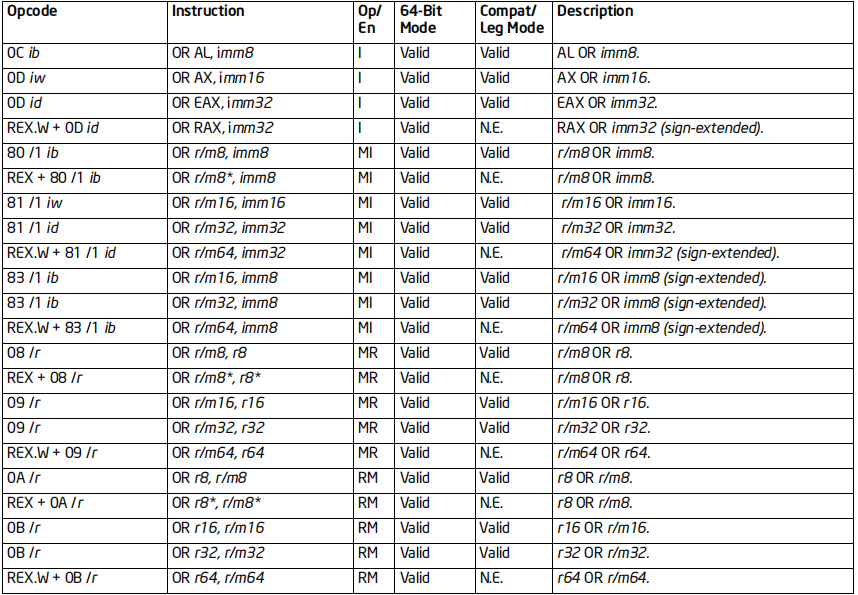
备注:
8位寄存器:
BPL = RBP的低八位
DIL = RDI的低八位
SIL = RSI的低八位
SPL = RSP的低八位
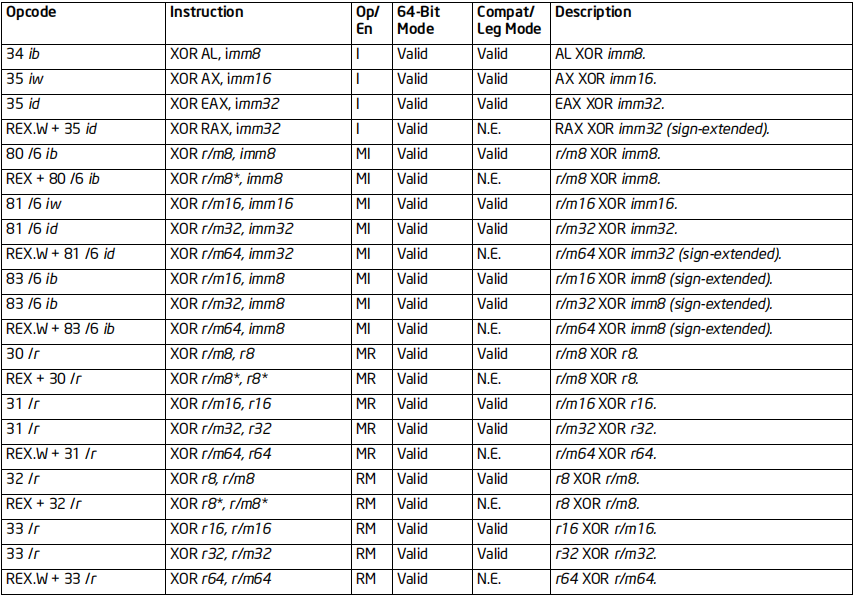
XOR指令
格式:XOR 目标,源
标志位的影响:OF、CF清零;SF、ZF、PF影响;AF未定义
效果:将目标和源按位进行异或运算,结果存入目标中
64位支持:部分情况不支持(64位下不支持AH,BH,CH,DH)
位移指令
SAL/SHL指令
格式:SAL/SHL 目标, 次数
标志位的影响:CF
效果:按照指定次数左移若干位,最高位移入CF,CF原来的值丢弃,低位填0
64位支持:支持
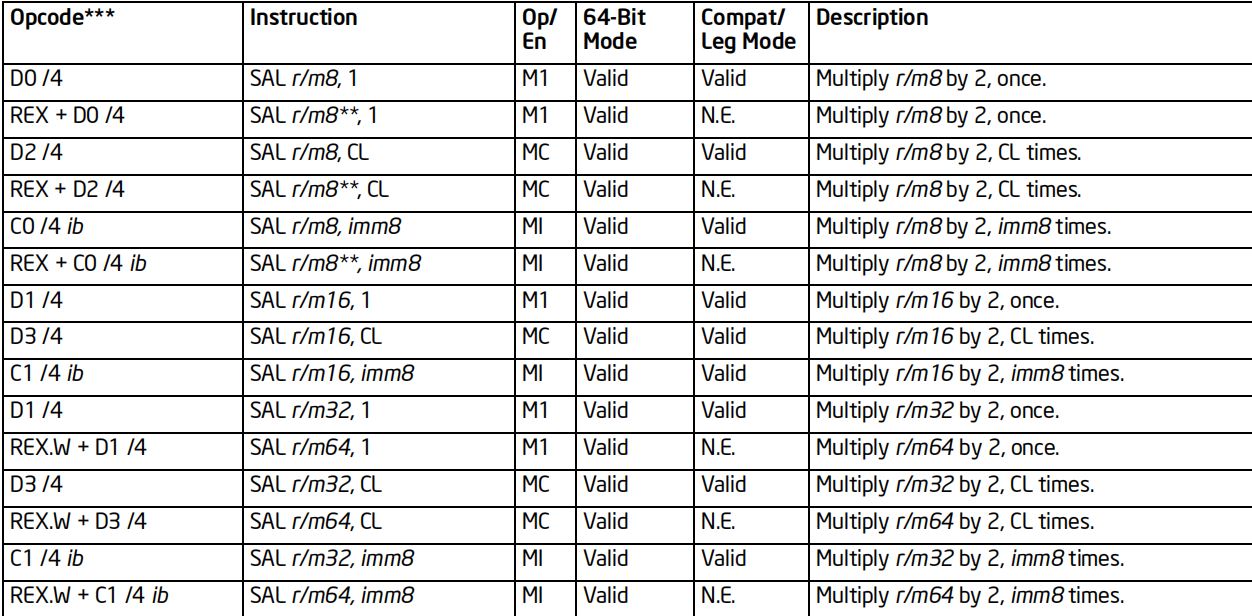
备注:SAL算术左移 SHL逻辑左移
两个指令是等效的!!
SAR指令
格式:SAR 操作数, 次数
标志位的影响:CF
效果:按照指定次数向右移若干位,最低位进入CF,符号位扩展,CF原来值丢弃
64位支持:支持
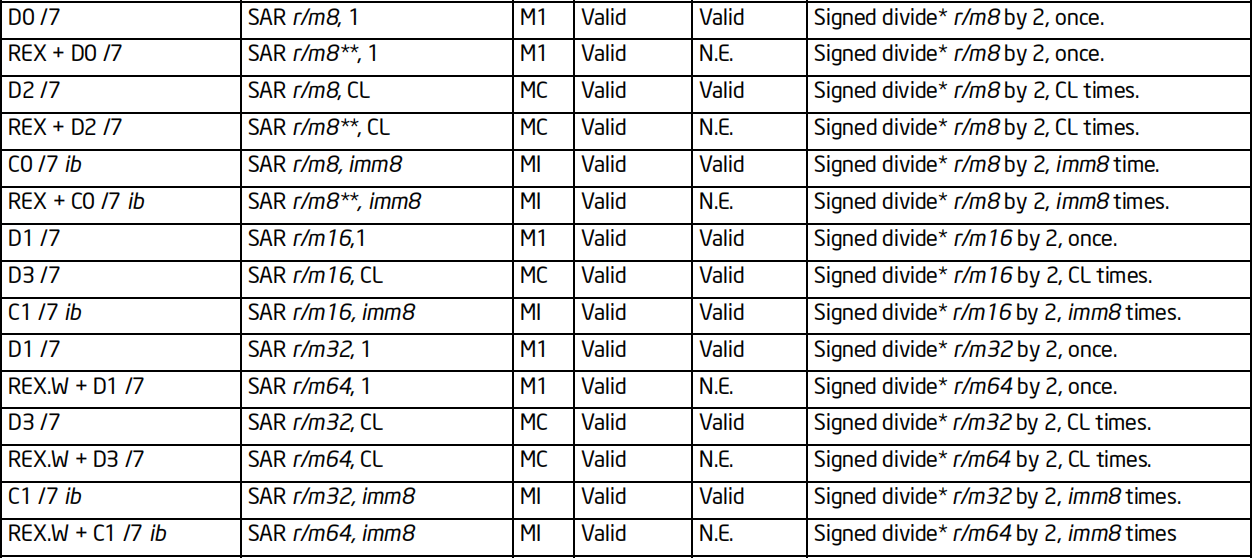
备注:算术右移
SHR指令
格式:SHR 操作数,次数
标志位的影响:CF
效果:按照指定次数右移若干位,最低位进入CF,最高位填0,CF原来值丢弃
64位支持:支持
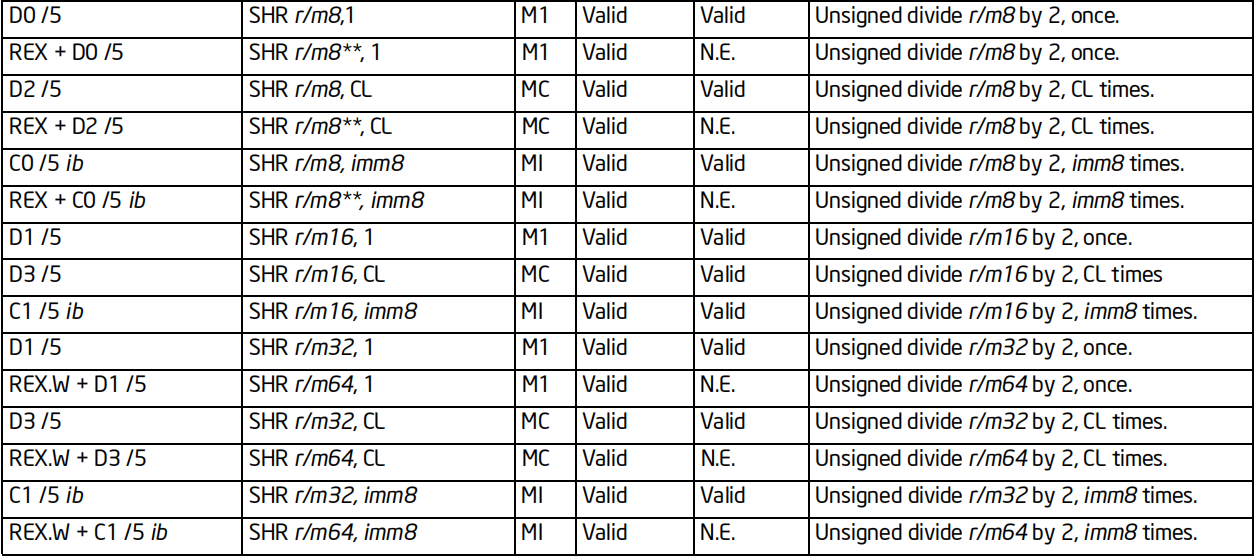
备注:逻辑右移
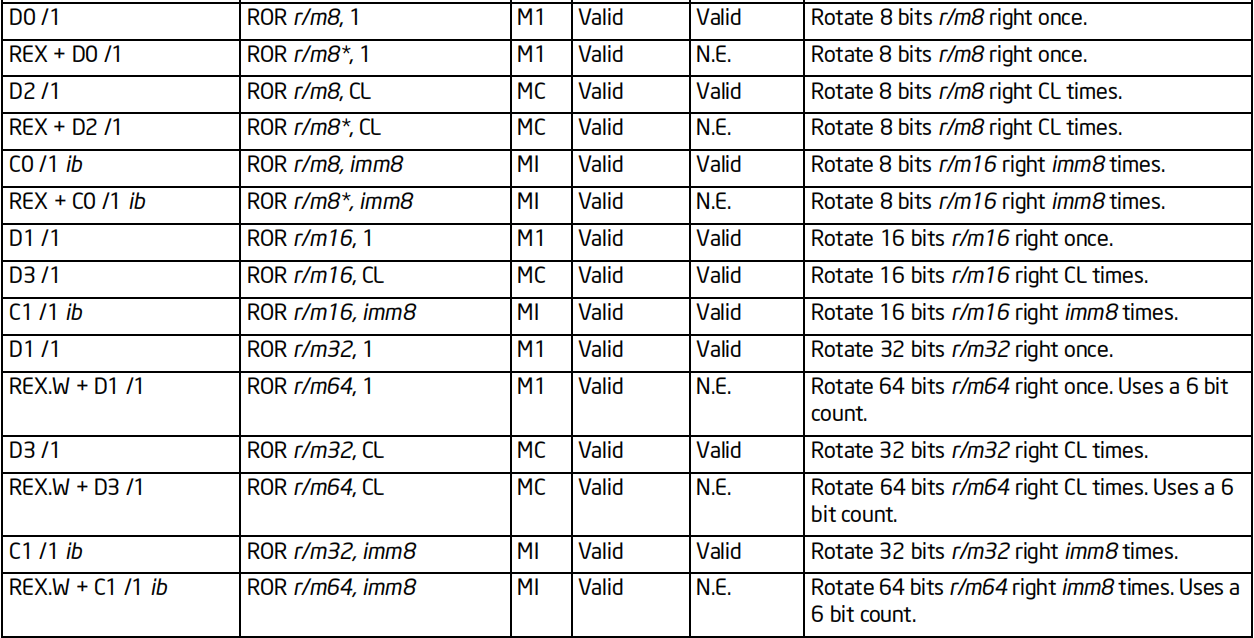
循环指令
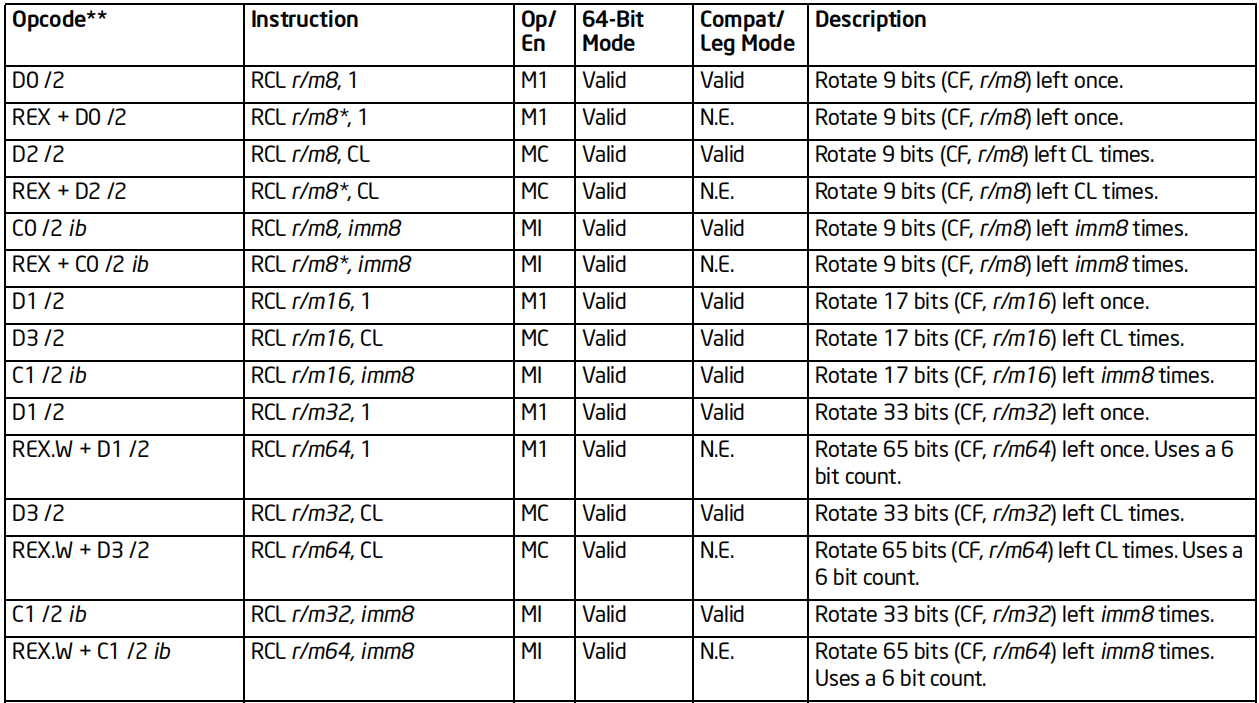
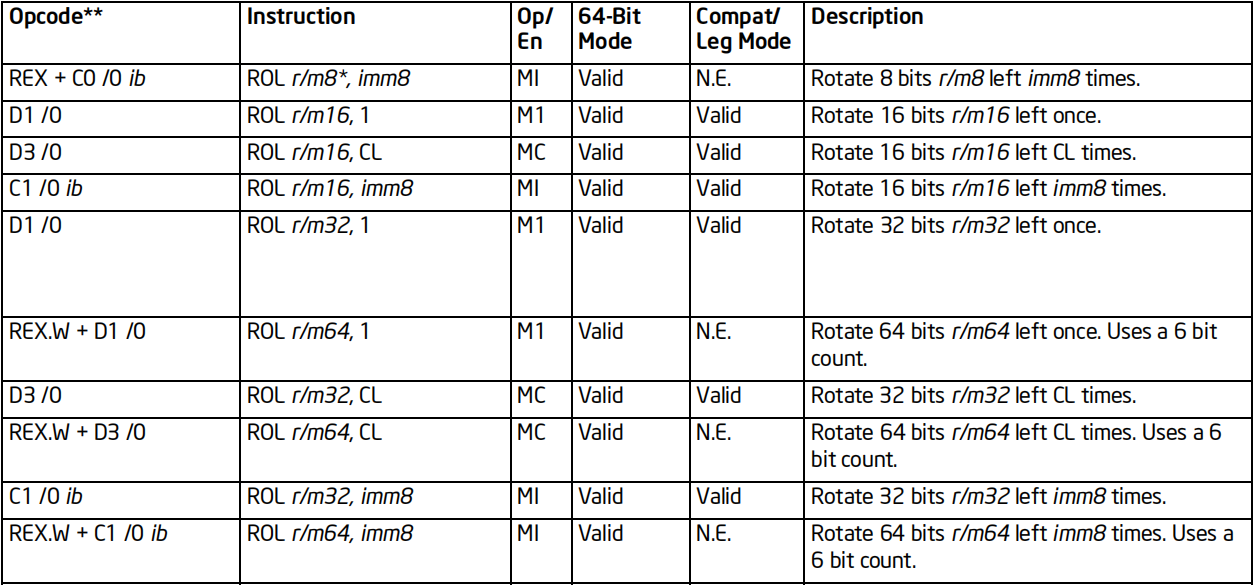
RCL/ROL指令
格式:RCL/ROL 操作数,次数
标志位的影响:CF
效果:
RCL将操作数按照指定次数,循环左移若干位;最高位移入CF,CF移入最低位
ROL将操作数按照指定次数,循环左移若干位;最高位移入CF和最低位,CF原值丢弃
64位支持:支持

RCR/ROR指令
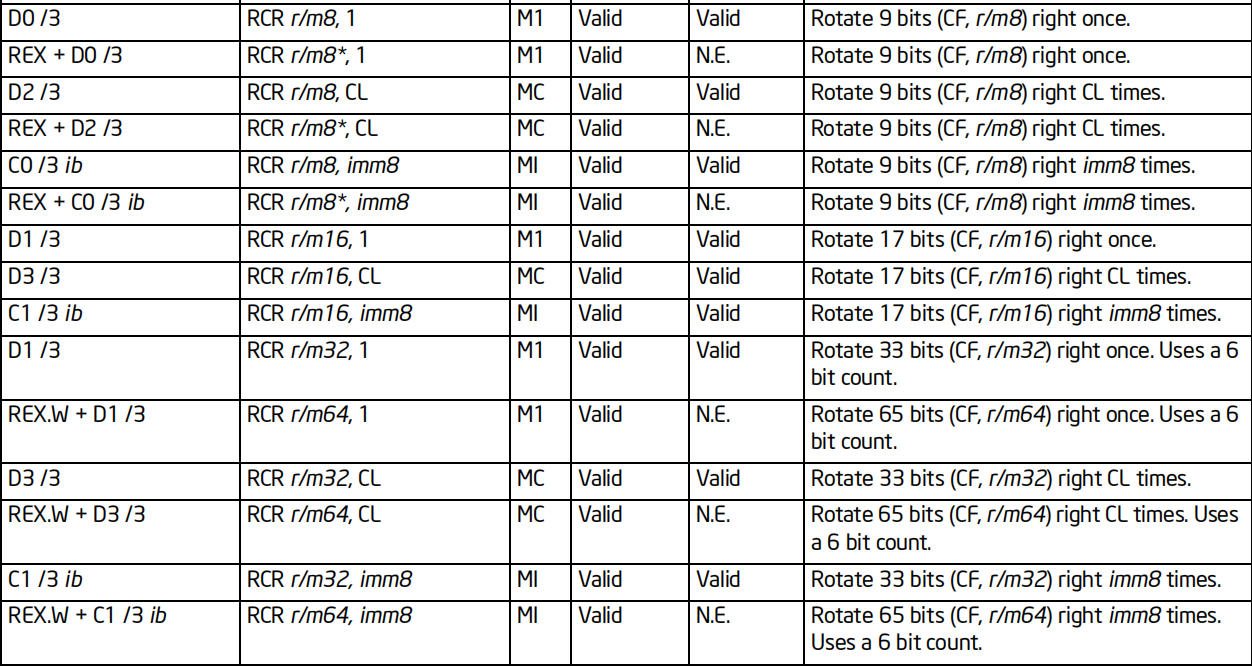
格式:RCR/ROR 操作数,次数
标志位的影响:CF
效果:
RCR 按照指定次数循环右移若干位,CF填入最高位,最低位填入CF
ROR按照指定次数循环右移若干位,最低位填入最高位和CF
64位支持:支持
系统调用
1 开发环境搭建
Dosbox安装
可以从官网https://www.dosbox.com/download.php?main=1
下载下面的安装程序

下载之后,运行安装程序(需要管理员权限)
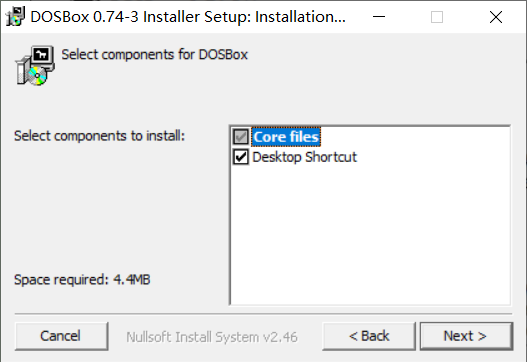
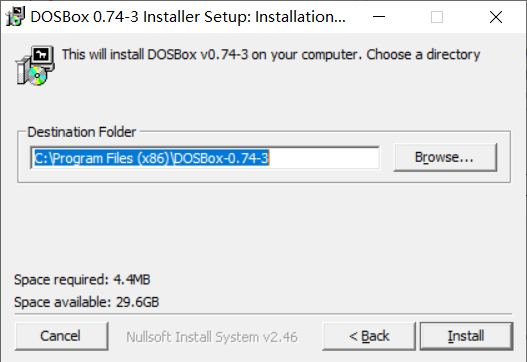
配置dosbox
在安装目录早点这个批处理命令,双击运行
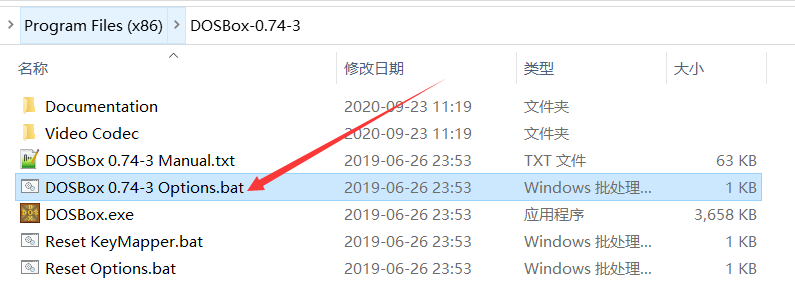
或者搜索文件dosbox-0.74-3.conf
找到文件最后的地方

[autoexec]
# Lines in this section will be run at startup.
# You can put your MOUNT lines here.
MOUNT C E:\Project\DosProj
C:
SET PATH=Z:\;C:\tools;C:\MASM611\BIN;C:\MASM611\BINR
将上面红色的内容添加到文件,保存并推出
注意,路径里面不能有英文、空格、特殊符号等等
快捷键
Alt+Enter //切换全屏
Alt+Pause //暂停模拟
Ctrl+F1 //改变键盘映射
Ctrl+Alt+F5 //开始/停止录制视频
Ctrl+F4 //交换挂载的磁盘映像,也就是更新磁盘文件
Ctrl+F5 //截图
Ctrl+F6 //开始/停止录制声音
Ctrl+F7 //减少跳帧
Ctrl+F8 //增加跳帧
Ctrl+F9 //关闭DOSBOX
Ctrl+F10 //捕捉/释放鼠标
Ctrl+F11 //模拟减速
Ctrl+F12 //加速模拟
Alt+F12 //不锁定速度
MASM的安装
复制安装文件夹到DosProj
然后启动dosbox
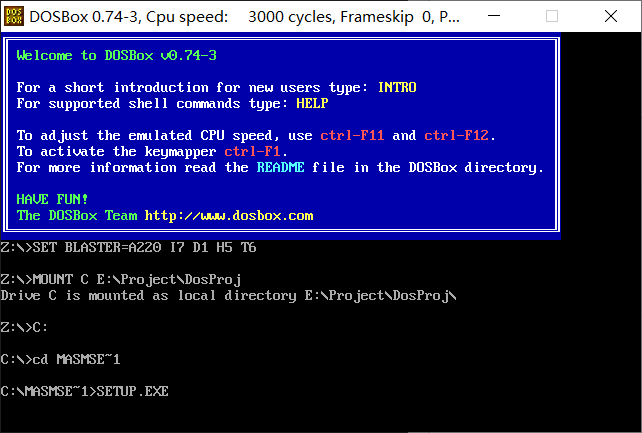
输入命令,如上图
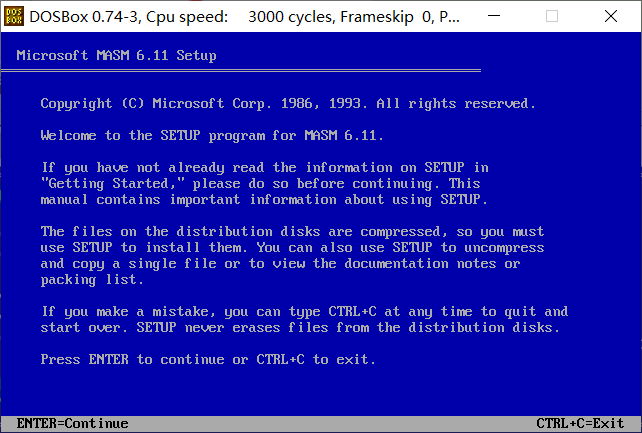
按下回车继续
选择第二个
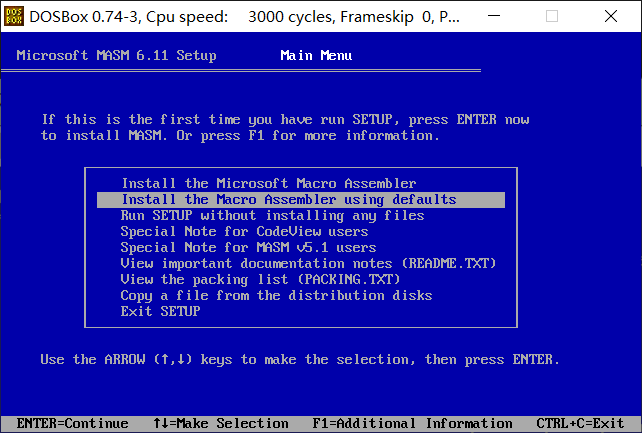
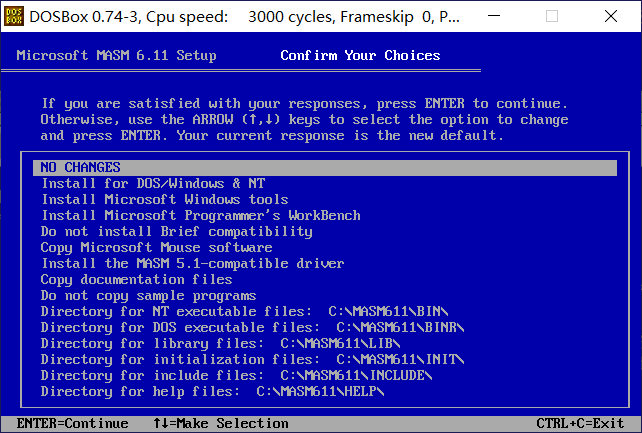
如果需要修改某项,可以选择进行修改
没有修改的需求的话,就选择NO CHANGES
然后开启安装程序
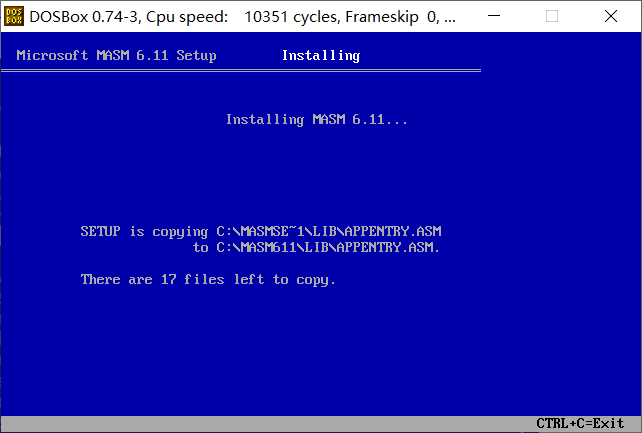
成功安装后,如下图
查看环境设置
查看系统设置
最后选择Exit SETUP结束安装程序
编译汇编
首先准备一个汇编文件
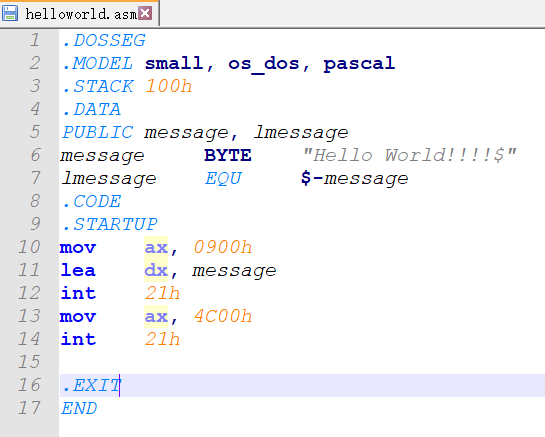
.DOSSEG
.MODEL small, os_dos, pascal
.STACK 100h
.DATA
PUBLIC message, lmessage
message BYTE "Hello World!!!$"
lmessage EQU $-message
.CODE
.STARTUP
mov ax, 0900h
lea dx, message
int 21h
mov ax, 4C00h
int 21h
.EXIT
END
然后执行编译命令
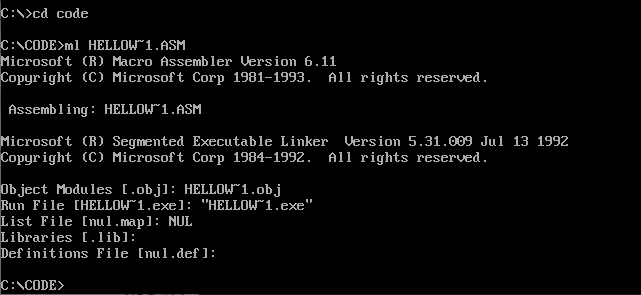
这样就可以生成hellow~1.exe程序
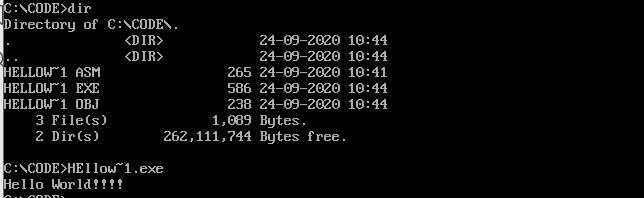
执行exe即可看到hello world
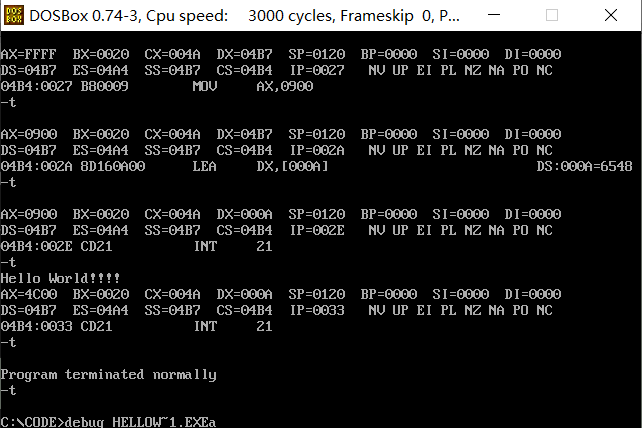
也可以执行debug HELLOW~1.exe进行调试
2 中断简述
中断是指计算机运行过程中,出现某些意外情况需主机干预时,机器能自动停止正在运行的程序并转入处理新情况的程序,处理完毕后又返回原被暂停的程序继续运行。
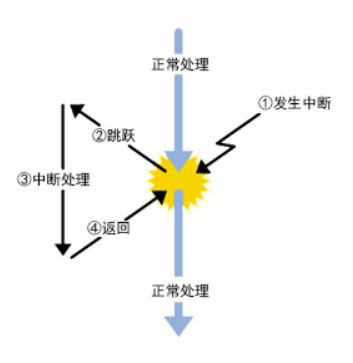
按照事件发生的顺序,中断过程包括 :
[①中断源发出中断请求;]{.underline}
[②判断当前处理机是否允许中断和该中断源是否被屏蔽;]{.underline}
[③优先权排队;]{.underline}
[④处理机执行完当前指令或当前指令无法执行完,则立即停止当前程序,保护断点地址和处理机当前状态,转入相应的中断服务程序;]{.underline}
⑤执行中断服务程序;
⑥恢复被保护的状态,执行"中断返回"指令回到被中断的程序或转入其他程序。
上述过程中前四项操作是由硬件完成的,后两项是由软件完成的。
3 硬中断和软中断
硬件中断(Hardware Interrupt)
可屏蔽中断(maskable
interrupt)。硬件中断的一类,可通过在中断屏蔽寄存器中设定位掩码来关闭。
非可屏蔽中断(non-maskable
interrupt,NMI)。硬件中断的一类,无法通过在中断屏蔽寄存器中设定位掩码来关闭。典型例子是时钟中断(一个硬件时钟以恒定频率—如50Hz—发出的中断)。
处理器间中断(interprocessor
interrupt)。一种特殊的硬件中断。由处理器发出,被其它处理器接收。仅见于多处理器系统,以便于处理器间通信或同步。
伪中断(spurious
interrupt)。一类不希望被产生的硬件中断。发生的原因有很多种,如中断线路上电气信号异常,或是中断请求设备本身有问题。
软件中断(Software Interrupt)
软件中断
是一条CPU指令,用以自陷一个中断。由于软中断指令通常要运行一个切换CPU至内核态(Kernel
Mode/Ring 0)的子例程,它常被用作实现系统调用(System call)。
4 DOS中断介绍
PC系统异常复杂,而且功能繁多
但是其中很多功能都是由驱动或者系统控制的
而这些代码都运行在系统内核层
普通用户根本无法直接调用
所以必须要有一种方式,能够让用户程序也能调用这些功能
否则就算系统能够支持这些设备的运行
用户也无法自由的使用这些设备
于是中断调用这种方式就产生了
下面所有的中断调用都是基于int 21h
通过AH传递需要调用的功能号
通过其他寄存器传递参数
最终实现各种功能的调用
AH 功能 调用参数 返回参数
00 程序终止(同INT 20H) CS=程序段前缀
01 键盘输入并回显 AL=输入字符
02 显示输出 DL=输出字符
03 异步通迅输入 AL=输入数据
04 异步通迅输出 DL=输出数据
05 打印机输出 DL=输出字符
06 直接控制台I/O DL=FF(输入)\ AL=输入字符
DL=字符(输出)
07 键盘输入(无回显) AL=输入字符
08 键盘输入(无回显)\ AL=输入字符
检测Ctrl-Break
09 显示字符串 DS:DX=串地址\
'$'结束字符串
0A 键盘输入到缓冲区 DS:DX=缓冲区首地址\ (DS:DX+1)=实际输入的字符数
(DS:DX)=缓冲区最大字符数
0B 检验键盘状态 AL=00 有输入
AL=FF 无输入
0C 清除输入缓冲区并\ AL=输入功能号\
请求指定的输入功能 (1,6,7,8,A)
0D 磁盘复位 清除文件缓冲区
0E 指定当前缺省的磁盘驱动器 DL=驱动器号 0=A,1=B,.… AL=驱动器数
0F 打开文件 DS:DX=FCB(File Operation Function)首地址 AL=00 文件找到
AL=FF 文件未找到
10 关闭文件 DS:DX=FCB首地址 AL=00 目录修改成功
AL=FF 目录中未找到文件
11 查找第一个目录项 DS:DX=FCB首地址 AL=00 找到
AL=FF 未找到
12 查找下一个目录项 DS:DX=FCB首地址\ AL=00 找到
(文件中带有*或?) AL=FF 未找到
13 删除文件 DS:DX=FCB首地址 AL=00 删除成功
AL=FF 未找到
14 顺序读 DS:DX=FCB首地址 AL=00 读成功
=01 文件结束,记录中无数据
=02 DTA空间不够
=03 文件结束,记录不完整
15 顺序写 DS:DX=FCB首地址 AL=00 写成功
=01 盘满
=02 DTA空间不够
16 建文件 DS:DX=FCB首地址 AL=00 建立成功
=FF 无磁盘空间
17 文件改名 DS:DX=FCB首地址\ AL=00 成功
(DS:DX+1)=旧文件名\ AL=FF 未成功
(DS:DX+17)=新文件名
19 取当前缺省磁盘驱动器 AL=缺省的驱动器号
0=A,1=B,2=C,.…
1A 置DTA地址 DS:DX=DTA(Disk Transfer Area)地址
1B 取缺省驱动器FAT信息 AL=每簇的扇区数111
DS:BX=FAT标识字节
CX=物理扇区大小
DX=缺省驱动器的簇数
1C 取任一驱动器FAT信息 DL=驱动器号 同上
21 随机读 DS:DX=FCB首地址 AL=00 读成功
=01 文件结束
=02 缓冲区溢出
=03 缓冲区不满
22 随机写 DS:DX=FCB首地址 AL=00 写成功
=01 盘满
=02 缓冲区溢出
23 测定文件大小 DS:DX=FCB首地址 AL=00 成功(文件长度填入FCB)
AL=FF 未找到
24 设置随机记录号 DS:DX=FCB首地址
25 设置中断向量 DS:DX=中断向量\
AL=中断类型号
26 建立程序段前缀 DX=新的程序段前缀
27 随机分块读 DS:DX=FCB首地址\ AL=00 读成功
CX=记录数 =01 文件结束
=02 缓冲区太小,传输结束
=03 缓冲区不满
28 随机分块写 DS:DX=FCB首地址\ AL=00 写成功
CX=记录数 =01 盘满
=02 缓冲区溢出
29 分析文件名 ES:DI=FCB首地址\ AL=00 标准文件
DS:SI=ASCIIZ串\ =01 多义文件
AL=控制分析标志 =02 非法盘符
2A 取日期 CX=年
DH:DL=月:日(二进制)
2B 设置日期 CX:DH:DL=年:月:日 AL=00 成功
=FF 无效
2C 取时间 CH:CL=时:分
DH:DL=秒:1/100秒
2D 设置时间 CH:CL=时:分\ AL=00 成功
DH:DL=秒:1/100秒 =FF 无效
2E 置磁盘自动读写标志 AL=00 关闭标志\
AL=01 打开标志
2F 取磁盘缓冲区的首址 ES:BX=缓冲区首址
30 取DOS版本号 AH=发行号,AL=版本
31 结束并驻留 AL=返回码\
DX=驻留区大小
33 Ctrl-Break检测 AL=00 取状态\ DL=00 关闭Ctrl-Break检测
=01 置状态(DL)\ =01 打开Ctrl-Break检测
DL=00 关闭检测\
=01 打开检测
35 取中断向量 AL=中断类型 ES:BX=中断向量
36 取空闲磁盘空间 DL=驱动器号 \ 成功:AX=每簇扇区数
0=缺省,1=A,2=B,.… BX=有效簇数
CX=每扇区字节数
DX=总簇数
失败:AX=FFFF
38 置/取国家信息 DS:DX=信息区首地址 BX=国家码(国际电话前缀码)
AX=错误码
39 建立子目录(MKDIR) DS:DX=ASCIIZ串地址 AX=错误码
3A 删除子目录(RMDIR) DS:DX=ASCIIZ串地址 AX=错误码
3B 改变当前目录(CHDIR) DS:DX=ASCIIZ串地址 AX=错误码
3C 建立文件 DS:DX=ASCIIZ串地址\ 成功:AX=文件代号
CX=文件属性 错误:AX=错误码
3D 打开文件 DS:DX=ASCIIZ串地址\ 成功:AX=文件代号
AL=0 读\ 错误:AX=错误码
=1 写\
=3 读/写
3E 关闭文件 BX=文件代号 失败:AX=错误码
3F 读文件或设备 DS:DX=数据缓冲区地址\ 读成功:
BX=文件代号\ AX=实际读入的字节数
CX=读取的字节数 AX=0 已到文件尾
读出错:AX=错误码
40 写文件或设备 DS:DX=数据缓冲区地址\ 写成功:
BX=文件代号\ AX=实际写入的字节数
CX=写入的字节数 写出错:AX=错误码
41 删除文件 DS:DX=ASCIIZ串地址 成功:AX=00
出错:AX=错误码(2,5)
42 移动文件指针 BX=文件代号\ 成功:DX:AX=新文件指针位置
CX:DX=位移量\ 出错:AX=错误码
AL=移动方式(0:从文件头绝对位移,1:从当前位置相对移动,2:从文件尾绝对位移)
43 置/取文件属性 DS:DX=ASCIIZ串地址\ 成功:CX=文件属性
AL=0 取文件属性\ 失败:CX=错误码
AL=1 置文件属性\
CX=文件属性
44 设备文件I/O控制 BX=文件代号\ DX=设备信息
AL=0 取状态\
=1 置状态DX\
=2 读数据\
=3 写数据\
=6 取输入状态\
=7 取输出状态
45 复制文件代号 BX=文件代号1 成功:AX=文件代号2
失败:AX=错误码
46 人工复制文件代号 BX=文件代号1\ 失败:AX=错误码
CX=文件代号2
47 取当前目录路径名 DL=驱动器号\ (DS:SI)=ASCIIZ串
DS:SI=ASCIIZ串地址 失败:AX=出错码
48 分配内存空间 BX=申请内存容量 成功:AX=分配内存首地
失败:BX=最大可用内存
49 释放内容空间 ES=内存起始段地址 失败:AX=错误码
4A 调整已分配的存储块 ES=原内存起始地址\ 失败:BX=最大可用空间
BX=再申请的容量 AX=错误码
4B 装配/执行程序 DS:DX=ASCIIZ串地址\ 失败:AX=错误码
ES:BX=参数区首地址\
AL=0 装入执行\
AL=3 装入不执行
4C 带返回码结束 AL=返回码
4D 取返回代码 AX=返回代码
4E 查找第一个匹配文件 DS:DX=ASCIIZ串地址\ AX=出错代码(02,18)
CX=属性
4F 查找下一个匹配文件 DS:DX=ASCIIZ串地址\ AX=出错代码(18)
(文件名中带有?或*)
54 取盘自动读写标志 AL=当前标志值
56 文件改名 DS:DX=ASCIIZ串(旧)\ AX=出错码(03,05,17)
ES:DI=ASCIIZ串(新)
57 置/取文件日期和时间 BX=文件代号\ DX:CX=日期和时间
AL=0 读取\ 失败:AX=错误码
AL=1 设置(DX:CX)
58 取/置分配策略码 AL=0 取码\ 成功:AX=策略码
AL=1 置码(BX) 失败:AX=错误码
59 取扩充错误码 AX=扩充错误码
BH=错误类型
BL=建议的操作
CH=错误场所
5A 建立临时文件 CX=文件属性\ 成功:AX=文件代号
DS:DX=ASCIIZ串地址 失败:AX=错误码
5B 建立新文件 CX=文件属性\ 成功:AX=文件代号
DS:DX=ASCIIZ串地址 失败:AX=错误码
5C 控制文件存取 AL=00封锁\ 失败:AX=错误码
=01开启\
BX=文件代号\
CX:DX=文件位移\
SI:DI=文件长度
62 取程序段前缀 BX=PSP地址
